
Understanding the Different Types of Storage
Scaleway just released its Block Storage in public beta and it is a great opportunity for us to explain the main differences between Block, File and Object storage.

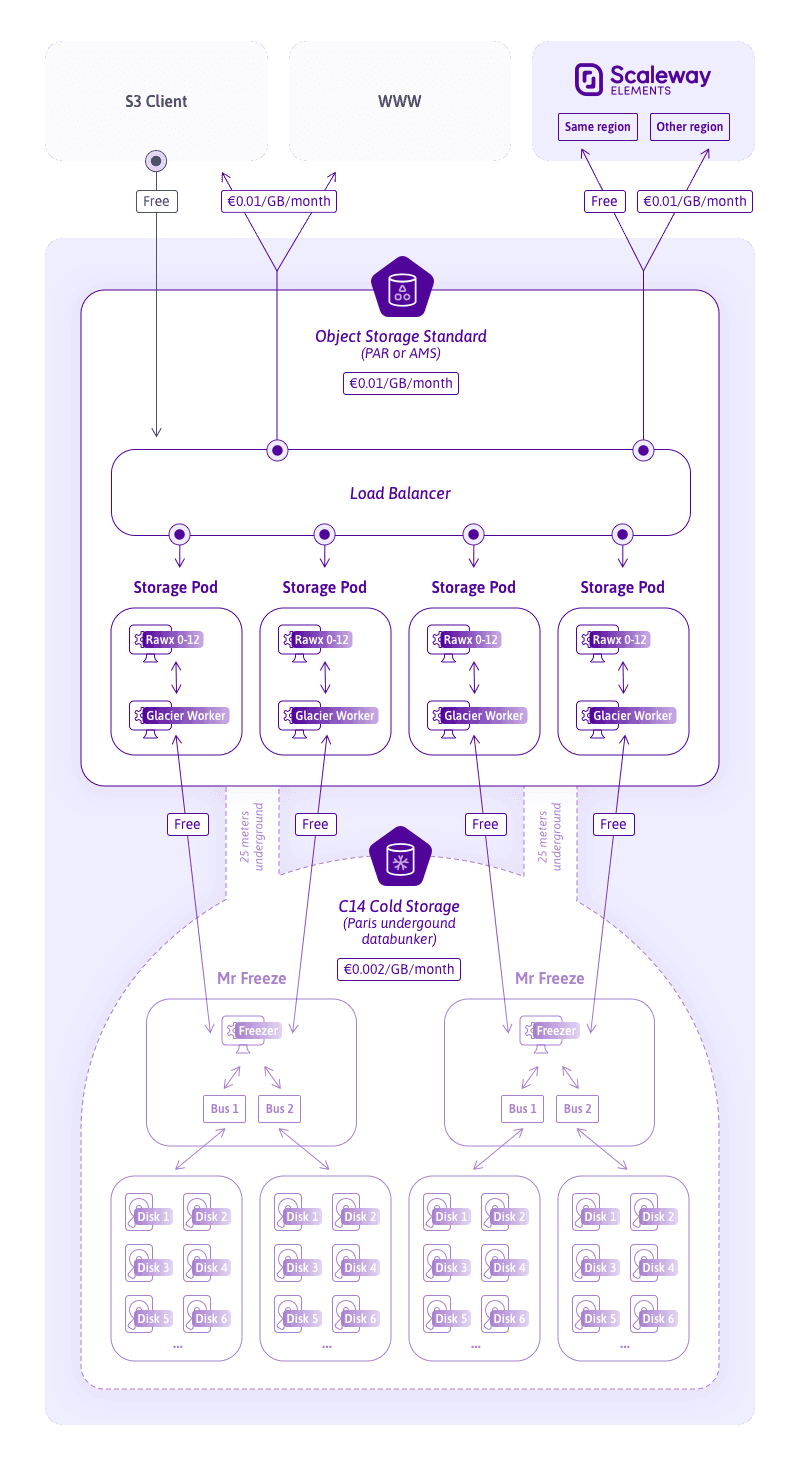
Scaleway Glacier is a storage class on the Scaleway Object Storage, built for archiving data at a low cost. It is not a product in itself, but rather an extension of our object storage, it cannot be accessed without the Object Storage API.
In this article, we will go over how this project was born and how it was developed as well as some technical insights on it.
In 2016, Scaleway Dedibox launched an archiving product: the C14 Classic, still available. The product was very hardware-centric, mainly built around two major aspects:
On the API side, C14 Classic was built like a vault: one opens a vault, puts data inside it, then closes the vault (archiving it). The main shortcoming with that design was that you needed to unarchive an entire archive to access a single file in it. In other words, to access a 1 GB file inside a 40 TB archive, you first needed to unarchive 40 TB.
The main concern with this design was the “Data front ends”, put another way, the big servers that were keeping the unarchived data. As you can imagine, multiple clients unarchiving multiple vaults of terabyte can fill up a server relatively quickly, thus blocking other clients from using the service.
In 2019, an internal Proof of Concept (PoC) was developed to demonstrate that we were able to use the C14 Classic hardware with the new Scaleway Object Storage. There were limitations, of course, but the PoC was very conclusive. Indeed, the C14 Classic hardware was rock stable, and the product turned out to be reliable with solid SLA. In addition, it also allowed us to use 40 PB of C14 hardware that was already in production.
As a result, huge efforts were deployed to transform the PoC in a production-ready project. A year later, the C14 Cold Storage beta was born at Scaleway.
First of all, the project was to be used with the Object Storage API. As a result, we needed a standard way to access the API. Lots of patches were deployed on our Object Storage
gateways to ensure compliance with Amazon’s S3 Glacier Storage class.
We also had to start working on a complete lifecycle engine, since the feature is required with the Scaleway Glacier.
Backed by 3 years of run, we learned a thing or two about archiving data, what works and what does not. The main objective was to build C14 Cold Storage around read optimisation, rather than write optimisation. We also decided to use file systems on the SMR disks, since in those 3 years, lots of patches were made in the Linux Kernel in order to optimise filesystems interaction with SMR disks.
MrFreeze is the name of the board that hosts the archiving solution. The board was made in-house, and we did not modify it for the Scaleway Glacier. It comes with the following:
As you can see, the main feature of the board is to have a lot of disks, but only two SATA buses to access them at the same time. Therefore only two disks can be powered on simultaneously. The board itself exposes a SATA line and power-line API through GPIO ports, and we keep a map on “what-to-power” in order to switch-on disk X or Y on the software side.
One funny quirk of this design is that we do not need to cool down the boards
that much, since 54 disks are powered down all the time, and the heat
dissipation works well. In addition, a whole rack with 9.8 PB of storage consumes less than 600W (22 chassis * 56 disks * 8 TB/disk)
The main caveat, of course, is that a disk needs some time to be powered on:
around 15 seconds from power-on to mountable by the userspace.
The disk that we use to fill those boards are 8TB Seagate SMR
Disks. These disks are built for storage density, and thus are perfect for data archiving. They can be quite slow, especially for writes, but it is a downside that comes with all SMR disks.
The C14 racks are located in our Parisian datacenters, DC2 and DC4, also known as The Bunker. Since one rack is around 1 metric ton of disks, we cannot place them wherever we want; for example, a MrFreeze rack in our AMS datacenter is totally out the question. So, we need to be able to transfer data from the AMS Datacenter (or WAW Datacenter) to the ones located in Paris.
The Freezer is the software that operates the MrFreeze board. It is responsible
for powering disks on and off, and actually writing data on them. It’s a very
‘simple’ software however, since all the database and intelligence are in the worker,
which is on far more powerful machines.
The Freezer communicates with the worker over a TCP connection, and exposes
a basic binary API:
typedef enum { ICE_PROBE_DISK = 0, /*!< Probe a disk for used and total size */ ICE_DISK_POWER_ON, /*!< Power on a disk */ ICE_DISK_POWER_OFF, /*!< Power off a disk */ ICE_SEND_DATA, /*!< Send data */ ICE_GET_DATA, /*!< Get data */ ICE_DEL_DATA, /*!< Delete data */ ICE_SATA_CLEAN, /*!< Clean all the SATA buses, power off everything */ ICE_FSCK_DISK, /*!< Request for a filesystem integrity check on a disk */ ICE_LINK_DATA, /*!< Link data (zero copy) */ ICE_ERROR, /*!< Error reporting */} packet_type_t;For simplicity, we logically split the freezer in two parts, one per SATA bus.
So in reality, two workers are speaking to one freezer, each one with a
dedicated bus. We will not go into details about the freezer since it’s mainly
dumping data from a socket to an inode (or the opposite for a read), and performing
some integrity checks.
Before we explain how the actual worker works, we need to explain our Object Storage stack: once an object is created, it is split in erasure coded chunks (6+3), and a rawx is elected to store a chunk. The rawx is a simple binary much like the freezer, without the disk-power bit: It simply dumps a socket into an inode, or the opposite. So for an object, a minimum of 9 rawxs are used to store the actual data.
For hot storage, we do not need to go further than that. We have a rawx per disk
(mechanical or SSD), which means the chunk is accessible at all times. For C14 Cold
Storage, though, we need to go one step further and actually send the data to
the archiving disks.
In order to do that, we used golang rawx code, and added the following logic:
WRITE (PUT): notifies a program through an IPC socketREAD (GET): checks that the data is actually there, and if it is not, requests it through the IPCDELETEThe other end of the IPC socket is the actual C14 Cold Storage worker, which talks with all the rawx of a rack; there are 12 mechanical disks per rack, so one worker speaks with 12 different rawxs.
On a Write, the worker will transfer the data to the freezers with a low
priority, actually emptying the inode on the rawx. On a READ, it gets the data
from the freezer to the rawx with high-priority in order for it to be
accessible by the usual API.
The worker is the piece of software that links the object storage with the
archiving servers. It receives commands on an IPC, and executes them
asynchronously.
There are three main types of command that the worker can receive:
CREATE: A chunk has been created, we need to transfer it to the archivingGET: A chunk is requested, we need to get it from the freezers as soon asDELETE: A chunk has been deleted, we need to unlink the inode on the freezersIn case of a CREATE command, the job is executed in a best-effort manner which does not represent a blocker as the data is available if the client needs it, and we have plenty of space on the hot storage hard drives. When the job is executed, we elect a disk to store the chunk. Election is a straightforward process, as the goal is to use a minimal amount of disks in total, in order to not have too much time loss upon powering disks on and off.
Once we find an appropriate disk, the data is sent to the freezer, and we empty the inode on the hot storage. The inode itself is not deleted, only the content is. We then store the disk number along with other information in a database, in order to be able to retrieve the content later on.
In case of a GET, the job is executed as soon as we can. It’s in the top priority for scheduling, so the only thing keeping us from executing it is prior GET jobs. Once the job is executed, we simply get the data from the archiving server, and fill the inode on the hot-storage hard drive. We then set a time on that inode, usually around a day, in order to garbage collect it, and not fill empty space on the hot storage.
It is important to note that these mechanics have nothing to do with the restore route “Restore time”, as the restore API call does move the object from
glacier to standard (e.g. from archiving to hot storage).
As mentioned previously, the worker is linked with a SATA bus from the freezer. So the worker only handles 22 disks in total.
The lifecycle engine places itself between the API, rawx and the Object Storage gateway, creating and deleting bucket rules and scheduling the transitions or expiration jobs on the objects matching the rules. The architecture is a distributed system, with a lifecycle master that communicates with the gateway, schedules and dispatches jobs to lifecycle workers which are present on all storage pods.
The master keeps track of every job to execute while the lifecycle worker only executes the task it receives using the storage pod capacity as a temporary storage solution, while transferring the object to C14 Cold Storage and back. One of the main assets of the engine is that it can wait for workers to put the data back from C14 Cold Storage to rawx, that’s why it is also used to execute the restored Object Storage call which does not need any lifecycle rule on the bucket.
Enjoy the new C14 Cold Storage on the Scaleway Console and check out our documentation to learn more on how to use the Scaleway Glacier!
Scaleway just released its Block Storage in public beta and it is a great opportunity for us to explain the main differences between Block, File and Object storage.

In the digital world, preventing any unexpected incident, even a power or internet outage, becomes even more critical as your applications can hardly afford any downtime.

In this article, we will present the internal architecture of Scaleway Object Storage.