
Infrastructures for LLMs in the cloud
What do you need to know before getting started with state-of-the-art AI hardware like NVIDIA's H100 PCIe 5, or even Scaleway's Jeroboam or Nabuchodonosor supercomputers? Look no further...

In today's cloud computing era, ensuring system resilience and recoverability is crucial. As organizations increasingly rely on native cloud applications, a robust Disaster Recovery Plan (DRP) is essential. This comprehensive guide provides step-by-step instructions to build an effective DRP, explores various cloud disaster recovery options, and shares best practices for incident management.
Detailed diagrams and descriptions of your cloud application's architecture, including servers, databases, and network configurations.
Choosing the good strategy is always a point of hours of discussions or lectures, keep in mind that there is no reference architecture “ones that never fail”, it is more about balancing the risk of unavailability. Scaleway can help you on your project to choose the tailor-made approach to your project.
A directory of all DRP team members, their roles, and emergency contact details.
A dedicated and well-prepared disaster recovery team is crucial for effectively restoring services and mitigating the impact of disasters.
Essential Roles:
Ensure your team is on-call and ready to respond 24/7. Use tools like Splunk to manage on-call rotations and alerting.
Explicit documentation of backup locations and restoration processes.
Documentation: The Bedrock of Recovery
One of the fundamental pillars of a robust DRP is meticulous documentation and procedures to restore and recover backup. Comprehensive documentation serves as the go-to reference during an emergency, providing clear instructions and ensuring that everyone involved knows their roles and responsibilities.
At Scaleway we understand this, and we work hard to ensure that our users have always updated documentation.
Some conclusions about our researches:
An effective backup strategy is crucial to any disaster recovery plan. The 3-2-1 rule is a tried-and-true method that ensures data is reliably backed up and accessible in the event of a disaster. The rule is simple:
In a cloud context, this might involve:
Important Note: An untested backup is as good as no backup. Regularly test your backups to ensure they can be restored as expected.
Some Testing Procedures:
Scaleway provides a range of disaster recovery options designed to meet the specific needs of your applications. Explore popular solutions that can be customized to ensure resilience and reliability for your cloud infrastructure.
Overview: Regularly back up data and restore it in case of a disaster.
Pros:
Cons:
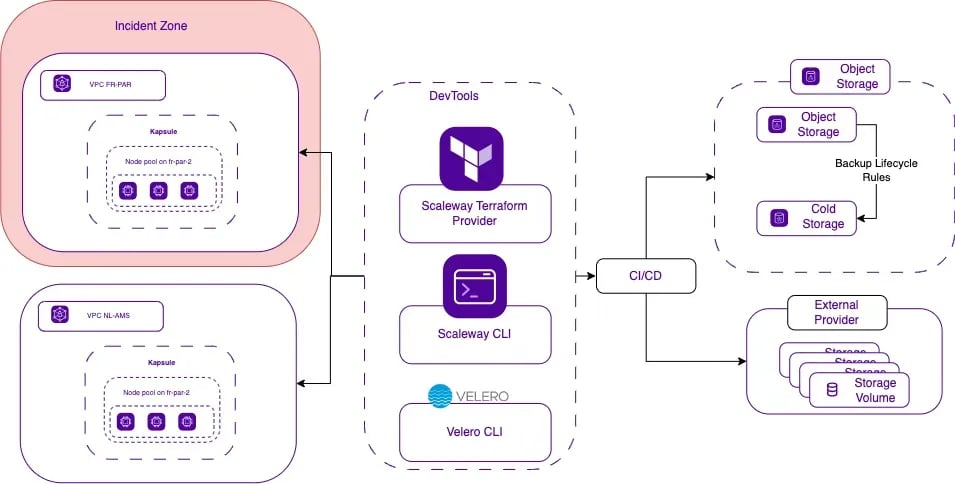
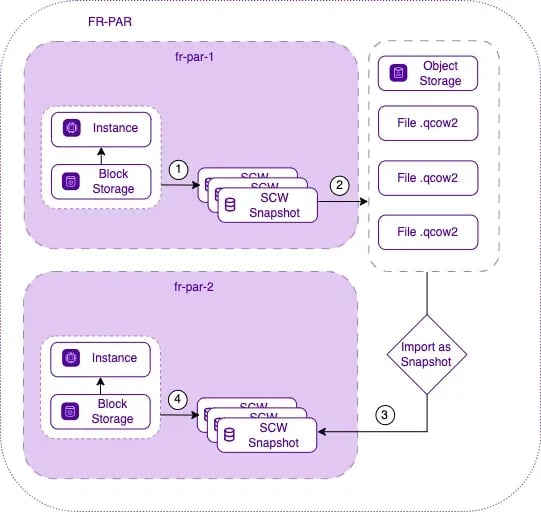
Here the mécanisme how to transfer snapshots in other Availability Zone in the same region:
Here how an architecture can be structured with an external provider:
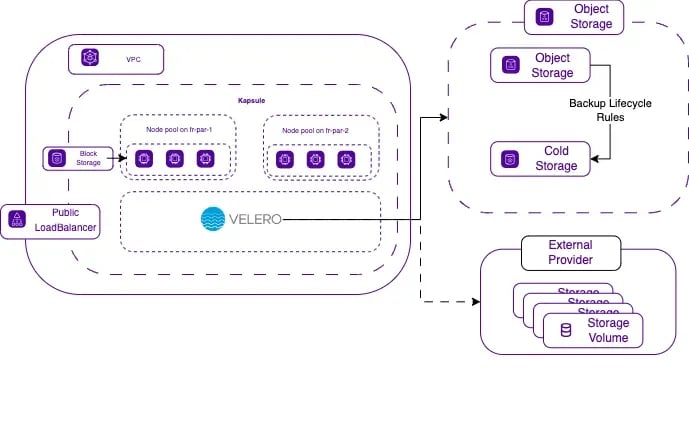
Overview: Maintain a minimal version of your application always running, which can be scaled up in the event of a disaster.
Pros:
Cons:
Overview: Keep a scaled-down but fully functional version of your application running in another region.
Pros:
Cons:
Overview: Run your application simultaneously in multiple regions, providing immediate failover capability.
Pros:
Cons:
Overview: Outsource disaster recovery to a third-party service provider that handles all aspects of the DRP.
Pros:
Cons:
Building a Disaster Recovery Plan is an ongoing process that requires regular updates and improvements. Do not forget the retention, frequency, security, restoring plan but this is subject for my next post. Stay proactive, and your application will remain resilient in the face of the next Black Swan.
What do you need to know before getting started with state-of-the-art AI hardware like NVIDIA's H100 PCIe 5, or even Scaleway's Jeroboam or Nabuchodonosor supercomputers? Look no further...

On February 13th, Scaleway encountered an incident in the FR-PAR region that impacted customers using the Kubernetes managed services. It was resolved the same day. Here's how!