Sacha Bernheim, Lead Site Reliability Engineer at Padok, rolls out K8s solutions for clients on a regular basis. Why is he such a fan of the cloud orchestrator? How does he push it to its limits? And how can it help with use cases as advanced as Terraform deployment and monitoring? Find out in this expert interview…
Do you and Kubernetes go back a long way?
I’ve always felt Kubernetes was going to be the next big thing. Back in engineering school, as part of the computer science association, we had to provide other students with an infrastructure where they could deploy things like their websites. This was always a nightmare, because they always needed VMs, but had no idea how to deploy on them. I felt containers would help a lot with the ecosystem’s diversity. Whether you’re coding in Node.js, Python, or PHP, starting Docker on a VM is always the same process. So I looked for a simpler way than VMs, and that was K8s. The association said no, because they felt it would be too hard to maintain. Whereas my experience with K8s is quite the contrary.
What’s so great about Kubernetes?
Well, quite a few things:
- K8s on a cloud service provider basically never crashes
- It’s easier to work with K8s’ abstraction than manually on a VM
- You know it’ll work, because you just have the Dockerfile, and every configuration that comes with it. This is way better for reproducibility: when K8s restarts, you know it’ll work. Whereas VMs tend to be changed manually, and it’s harder to track those changes
- The tooling ecosystem is incredible, the best example currently being ArgoCD, which deploys applications for you in your cluster and shows you in real time what’s happening
- It improves the developer experience, by providing the tooling necessary to generate on-demand preview environments; something Padok clients have been asking us for for years, but which was way more time-consuming and expensive before K8s.
Why are on-demand preview environments so crucial?
Because of the recent boom in microservices, we increasingly hear the question “how can my devs test in a prod-like environment when their local computers are not enough any more?” Indeed, testing 40+ services on your local computer before deploying in production is not an option. Microservices need to interact with a lot of other elements in your infrastructure, and you can’t reproduce that context locally. You could redeploy your whole cluster in another account, but that process is slow and costly. We also tried redeploying all of the applications inside the cluster. This helped with the speed issue, but it still cost a lot of money.** If you have 50 developers, you might need 100 more VMs, so that’s way too expensive**.
So what’s the solution? And its limits?
Our solution: only redeploy the one application you need to test within the cluster. With some network work, you can then re-route your traffic to the network you just created. This way, you deploy both the old and the new versions of an application at the same time, so you can decide which one you’re going to use when you do a request. This is way more cost-effective than redeploying 50 apps.
The issue here, however, remains databases, as you may need to run migrations on them, or create new ones with fake data inside… and we don’t currently have the free tooling we need to anonymize production data. There are some SaaS solutions already available for this, but nothing open source yet. It’s interesting that the whole community is trying to standardize how to do preview environments right now.
So today, you can either wait for the community to find a standardized solution, or put in place mechanisms that’ll copy everything for you. But this requires 1-2 months’ advance work for 1-2 people. And it can’t apply to fully event-driven architectures, because everything that’s asynchronous is too hard to do at the moment.
That’s right, or more specifically TACoS (TF automation and collaboration software). TACoS constantly checks your TF code to check:
- There’s no drift (when you have a difference between what’s written in your TF code, what it’s stored, and what it’s deployed with your CSP)
- And that code access control is properly managed.
For now, as is often the case, you have SaaS options like TF Cloud, Spacelift or env0, but these can be really expensive, as you pay by user, by which part of TF code you want to sync, and by each workflow that you’ll run. So it’s a high entry ticket for smaller companies. Open source alternatives exist, but they may not be complete, i.e. only offer drift detection, or CD/CD workflows, but none do both.
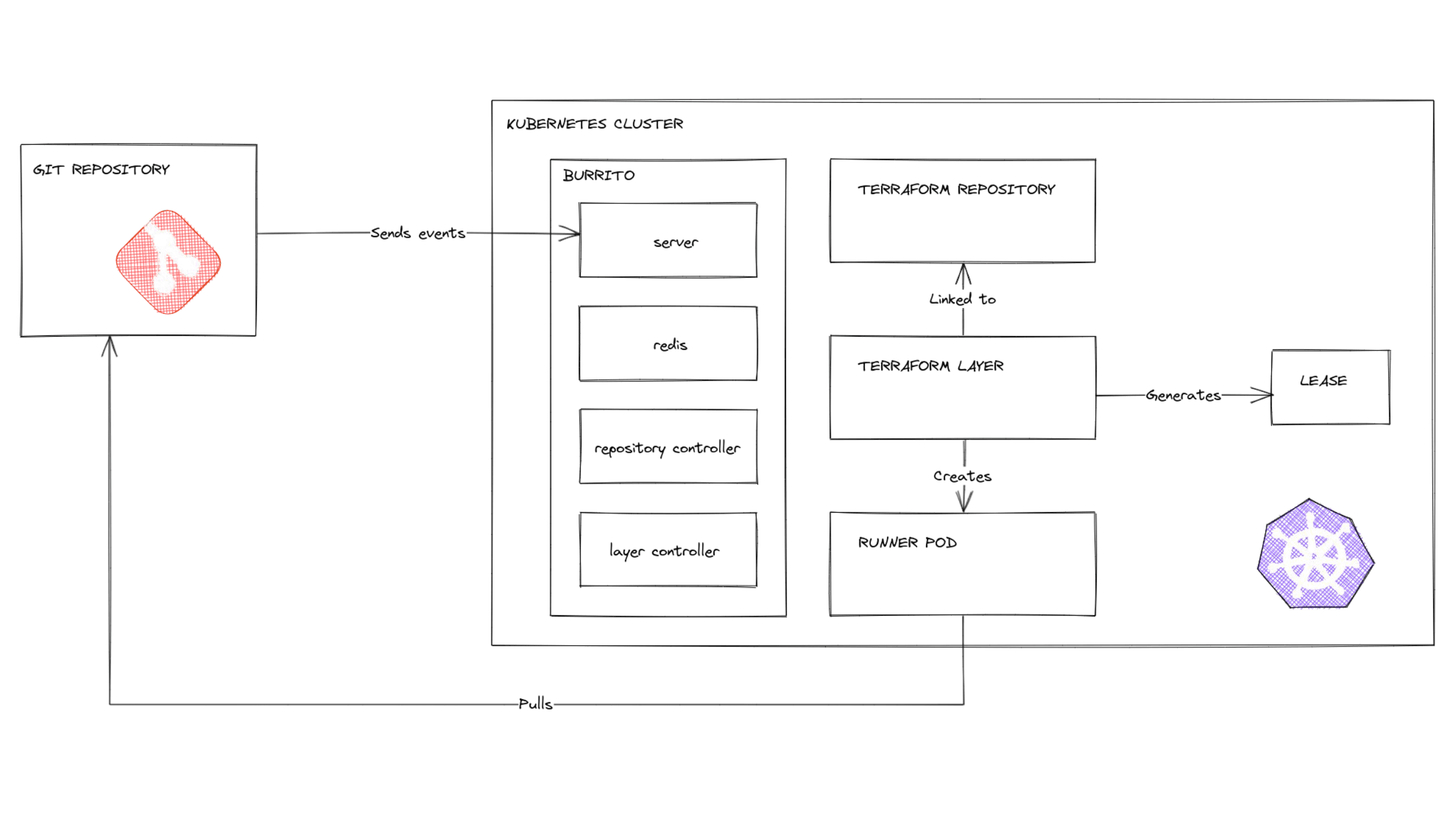
This is why, at Padok, we created a K8s operator to make our own TACoS. We wanted to use the power of K8s, for example its reconciliation pattern, which gave us a good base to work on. And naturally, we called it “Burrito”!
Everything in K8s works via reconciliation, not directly. I talk to the API, that talks to its database (etcd), and it doesn’t do anything else. So afterwards you have controllers that will regularly check what’s inside the API. It’s like cruise control in cars: you say you want to drive at 80km/h, something regularly checks the whole car to make sure you’re always traveling at that speed. In the etcd, we’ve stored the desired state of K8s, and reconciliation constantly checks the state inside the cluster.
Is Burrito going to work?
We’ve been working on Burrito for six months now. It’s taking a while, but we’re starting to have something that works properly. So we’re trying it internally with some TF code that we use at Padok at the moment. I’m confident, but it’s still experimental work; we're keen to check whether it works in the real world.
The main challenge is the conception. With K8s, every resource has a status, and there is a list of conditions that can be true or false at any time. So you have to think really hard about what happens if only one condition is true, or two, or none and so on. What really helped is that Red Hat created the Operator SDK, which bootstraps 1000s of lines of code for you that will connect to the K8s API, start the reconciliation and so on, so you can concentrate on the logic you want to implement.
This is precisely the beauty of Kubernetes: it allows you to concentrate purely on the conception, not on connections. Knowing you have something that will regularly check everything’s working helps a lot.