
AI in practice: Generating video subtitles
In this practical example, we roll up our sleeves and put Scaleway's H100 Instances to use by leveraging a couple of open source ML models to optimize our internal communication workflows.

Retrieval Augmented Generation (RAG) is one of the most sought-after solutions when using AI, and for good reason. It addresses some of the main limitations of Large Language Models (LLMs) such as a static knowledge base, inexact information, and hallucinations.
While there is a plethora of online material discussing RAG systems, most of them use high-level components that mask the building blocks composing a RAG pipeline. In this article, we’ll use a more grassroots approach to analyze the structure of such systems and build one using Scaleway’s elements, notably one of the latest entries in our portfolio: Managed Inference.
Let’s start by describing a typical use case. You want to build an assistant that can answer questions and provide precise information using your company’s data. You can do this by providing users with a chat application that leverages a foundation model to answer queries. Today, you can choose from a multitude of foundation models and quickly set up such a system. The problem is that none of these models were trained using your data, and even if they were, by the time you put your system into production, the data will already be stale.
This leaves you with two choices: either you create your own foundation model, or you take an existing one and fine-tune it using your company’s data. RAG provides a third way, that allows you to retrieve your own data based on user queries and use the retrieved information to pass an enriched context to a foundation model. The model then uses that context to answer the original query.
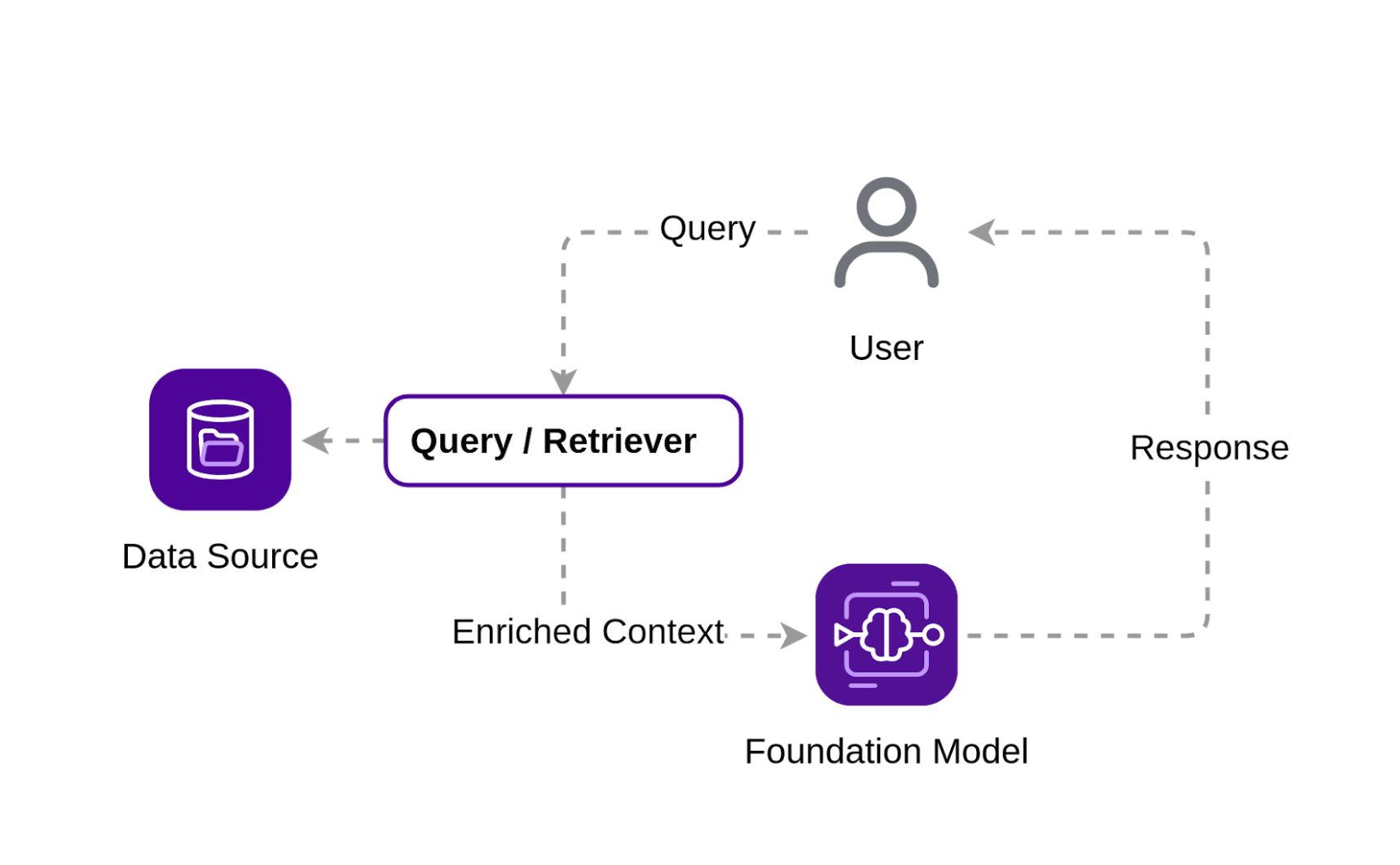
We now have enough information to identify the main components of our solution:
However, we are still missing some components. We need to ingest the raw data from our Data Source, like parse PDFs, scrape web pages, and so on. We need a Scraper/Parser component to achieve that.
Then, the raw data needs to be preprocessed before we can pass it to the Embeddings Model. We need to normalize and tokenize it properly before passing it as input to the embeddings model. The same goes for user queries; they must be normalized and tokenized using the same preprocessor. Thus, we have identified our missing components:
Now that we have all our puzzle pieces in place, a pattern emerges in the structure of our RAG pipeline. We can clearly identify two sub-systems:
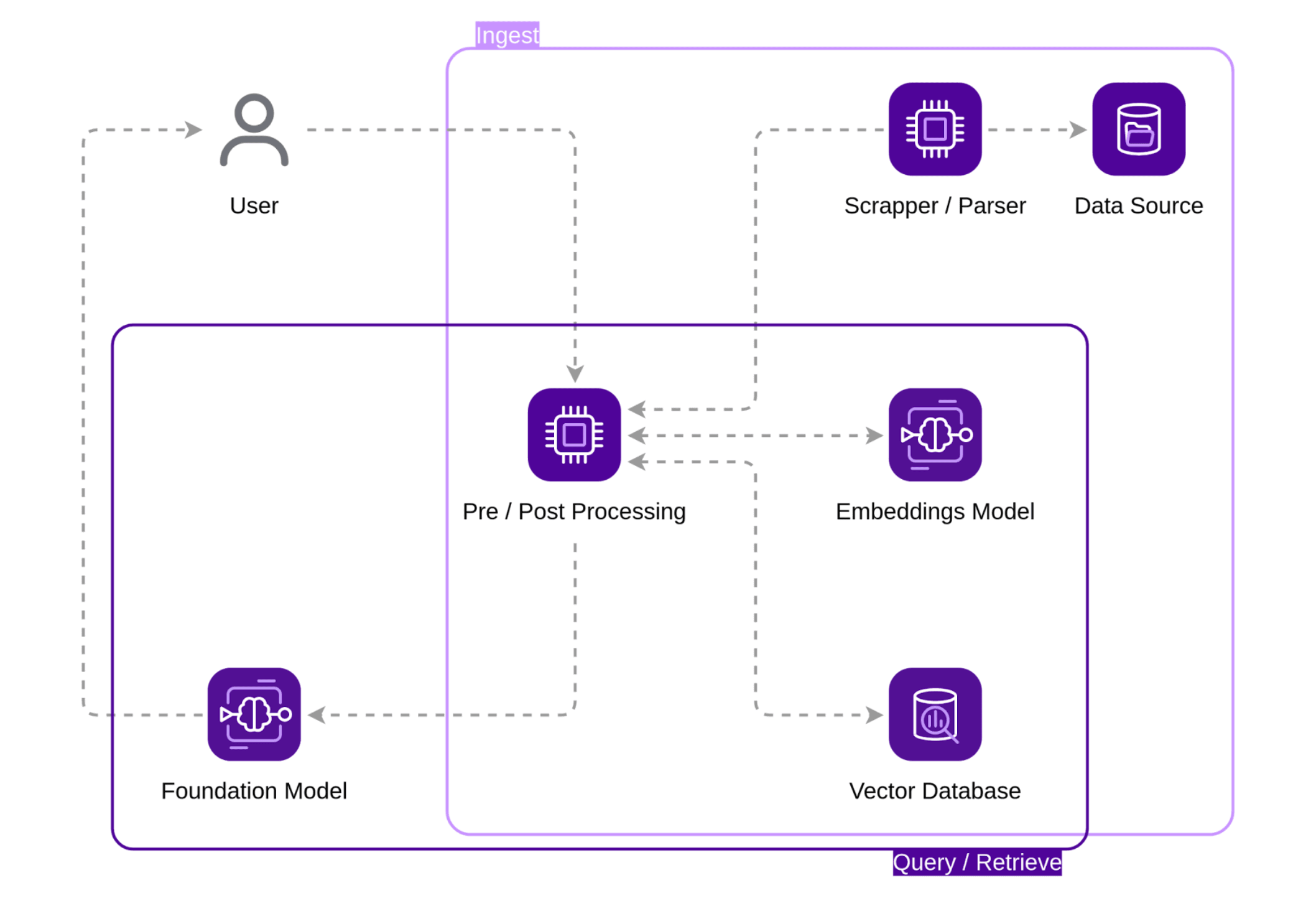
With this information, we can design the Ingest sub-system, which includes:
Fortunately, Scaleway offers most of these components as managed services, simplifying the implementation process.
Scaleway’s newly developed Managed Inference service, now in public beta, can be used to quickly and securely deploy an easy-to-use LLM endpoint based on a select list of open-source models. It can be used to deploy a scalable, ready-to-use Sentence-t5-xxl embedding model in less than 5 minutes. Check the Quickstart guide to learn how to create an embeddings endpoint. At the end of the Quickstart, you’ll end up with an endpoint in the form: https://
The same goes for the Vector Database. Scaleway provides a PostgreSQL Managed Database with a plethora of available extensions, one of which is the pgvector extension that enables vector support for PostgreSQL. Make sure to check the Quickstart guide to deploy a resilient production-ready vector database in just a few clicks.
This leaves us with the Scrapper/Parser and the Preprocessor. You can find sample implementations for these two components in the dedicated Github repository in the form of two services using a REST API.
Once Scaleway’s managed components and our sample implementations are in place, all we have to do is assemble them to obtain our Ingest pipeline.
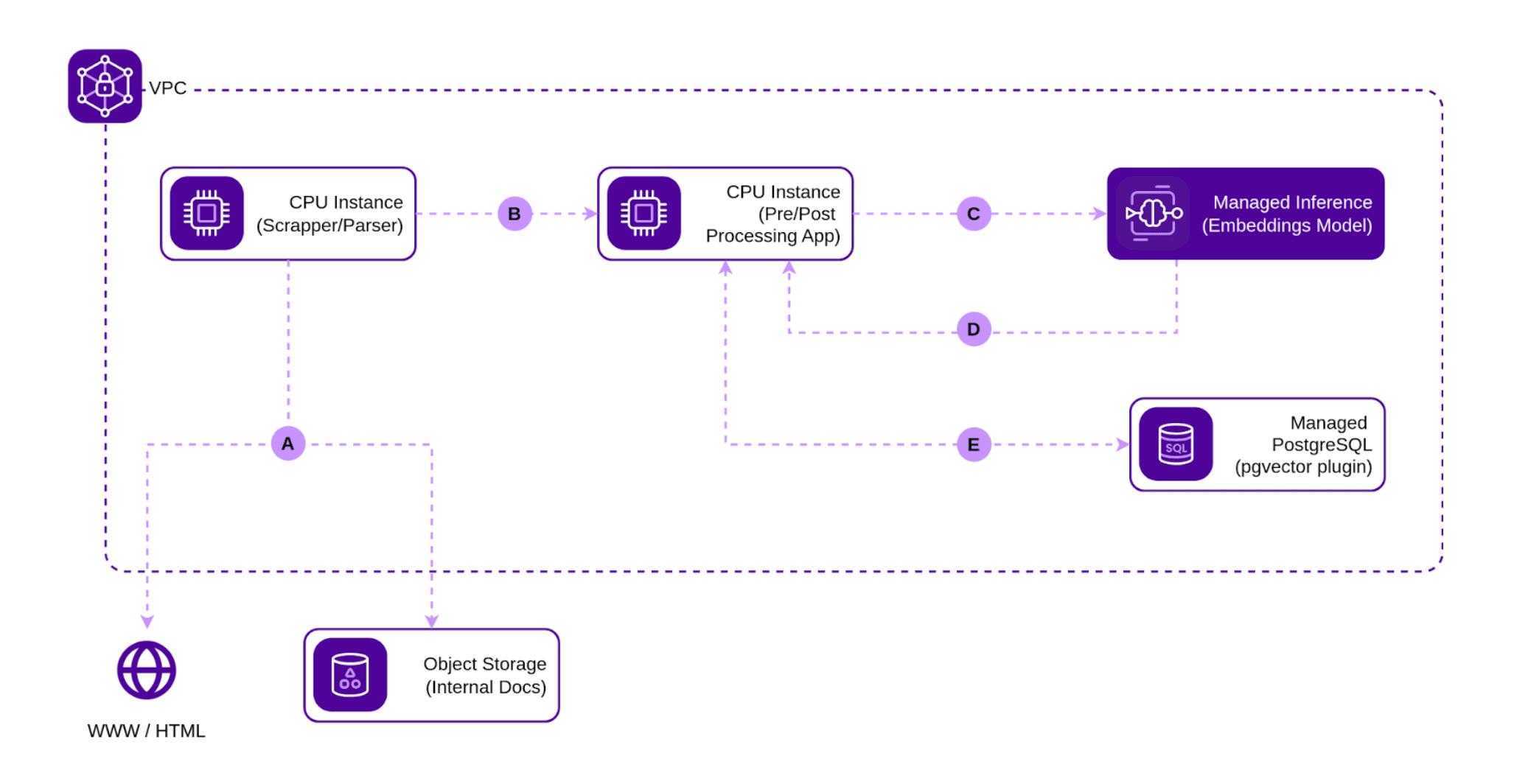
A. The Scraper/Parser pulls data from the external Data Sources. In this example, we’ll scrape information from Scaleway’s Github documentation and parse data from PDFs uploaded on Amazon S3-compatible Scaleway’s Object Storage.
B. The raw data is sent to the Preprocessor, which normalizes it and tokenizes it appropriately for the Embeddings Model provided via Scaleway’s Managed Inference.
C. The preprocessed data is sent to the Embeddings Model via a POST request using the endpoint generated once the service is started.
D. The Embeddings Model returns the generated vectors to the Preprocessor.
E. The Preprocessor stores the embeddings together with the associated data in the PostgreSQL database.
Thanks to Scaleway’s managed services, we have an Ingest pipeline up and running in no time.
This sub-system reuses some of the components of the Ingest sub-system. The Preprocessor, Managed PostgreSQL Database, and the Embeddings Model provided via the Managed Inference service are all reused. We still need a Foundation Model to which we can pass an enriched context as well as the chat interface that sends the user’s queries to it and receives the responses.
Once again, Scaleway’s Managed Inference comes to the rescue. You can use the same Quickstart guide as before, only this time we’ll use a Llama-3-8b-instruct as our Foundation Model. This is a perfect fit for our assistant.
A basic chat application is provided in the same Github repository as before.
Once we hook everything together, we have our Query/Retrieval sub-system:
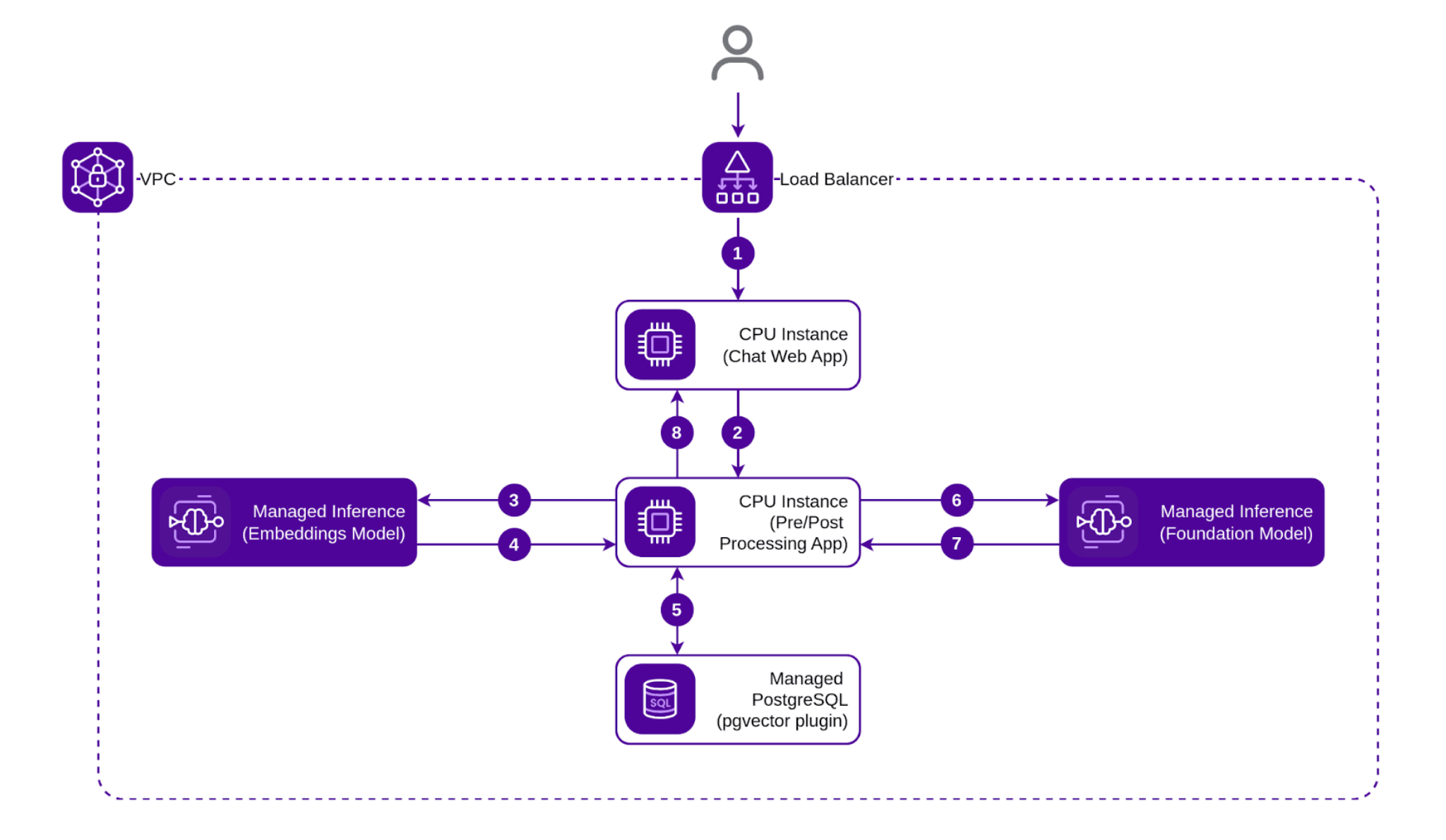
This is a basic example that illustrates the building blocks found throughout any RAG pipeline. By leveraging Scaleway’s managed services, you can quickly deploy an effective RAG system, allowing you to focus on fine-tuning and expanding your pipeline to meet specific requirements.
Building a RAG pipeline with managed solutions offered by Scaleway streamlines the process of implementing such systems. By leveraging components like Managed Inference for the embeddings and foundation models and a managed database like PostgreSQL with the pgvector extension, deployment becomes faster and more scalable, allowing businesses to focus more on fine-tuning their systems to meet specific needs.
However, there is more to a RAG system beyond the basics covered in this article. Different chunking strategies, such as different sentence tokenizers or splitters or adjacent sequence clustering, can significantly improve data processing and retrieval accuracy. Additionally, optimizing vector database retrieval methods using the pgvector extension can further enhance the system performance. For instance, using ivfflat iindex creation can greatly speed up similarity searches. Further fine-tuning by using the lists and probes parameters can also help in balancing between speed and accuracy.
In conclusion, while Scaleway’s managed solutions greatly simplify the setup and deployment of a RAG pipeline, as with any system, one has to strike a balance between speed and accuracy by exploring the different aspects of such solutions.
Thanks to Diego Coy for his extra research for this article!
In this practical example, we roll up our sleeves and put Scaleway's H100 Instances to use by leveraging a couple of open source ML models to optimize our internal communication workflows.
How can startups take their first steps with Large Language Models (LLMs)? Leveraging AI needn't cost the earth, explains MindMatch's Zofia Smoleń

RAG improves LLM's accuracy and reliability by incorporating external sources into the response generation pipeline. This makes using an LLM a more reliable and powerful tool for your AI applications