
Supervised Machine Learning done right: getting the labels that you want
Newly employed data scientists find that no amount of models and fine-tuning of hyperparameters can make up for the poor quality of their training data...

In addition to the labels that are required to train your supervised machine learning model, in reality, there are often additional annotations that you’ll need to get the model to perform adequately in production and for the results to align with your business objectives. These additional labels are our focus today.
While we are talking about this, I would like to show you how to go about annotating images or videos (whether by yourself or via a team of annotators) with the help of a new data annotation platform by Scaleway (a European cloud provider originating from France). This platform is called Smart Labeling and is currently available for free in Early Access (feel free to sign up here if you wish to use it).
Once you create a free Scaleway account and get notified that you have been added to Smart Labeling’s Private Beta program, start by creating an object storage bucket and uploading the images that you want to have labeled into it. (Scaleway’s Object Storage has a generous free tier that includes 75 GB of storage and outgoing transfer every month.)
Then click on Smart Labeling in the AI section of the side menu. If you have not created any Smart Labeling resources so far, you will be invited to create your first Labeling Workspace by clicking the green button below:
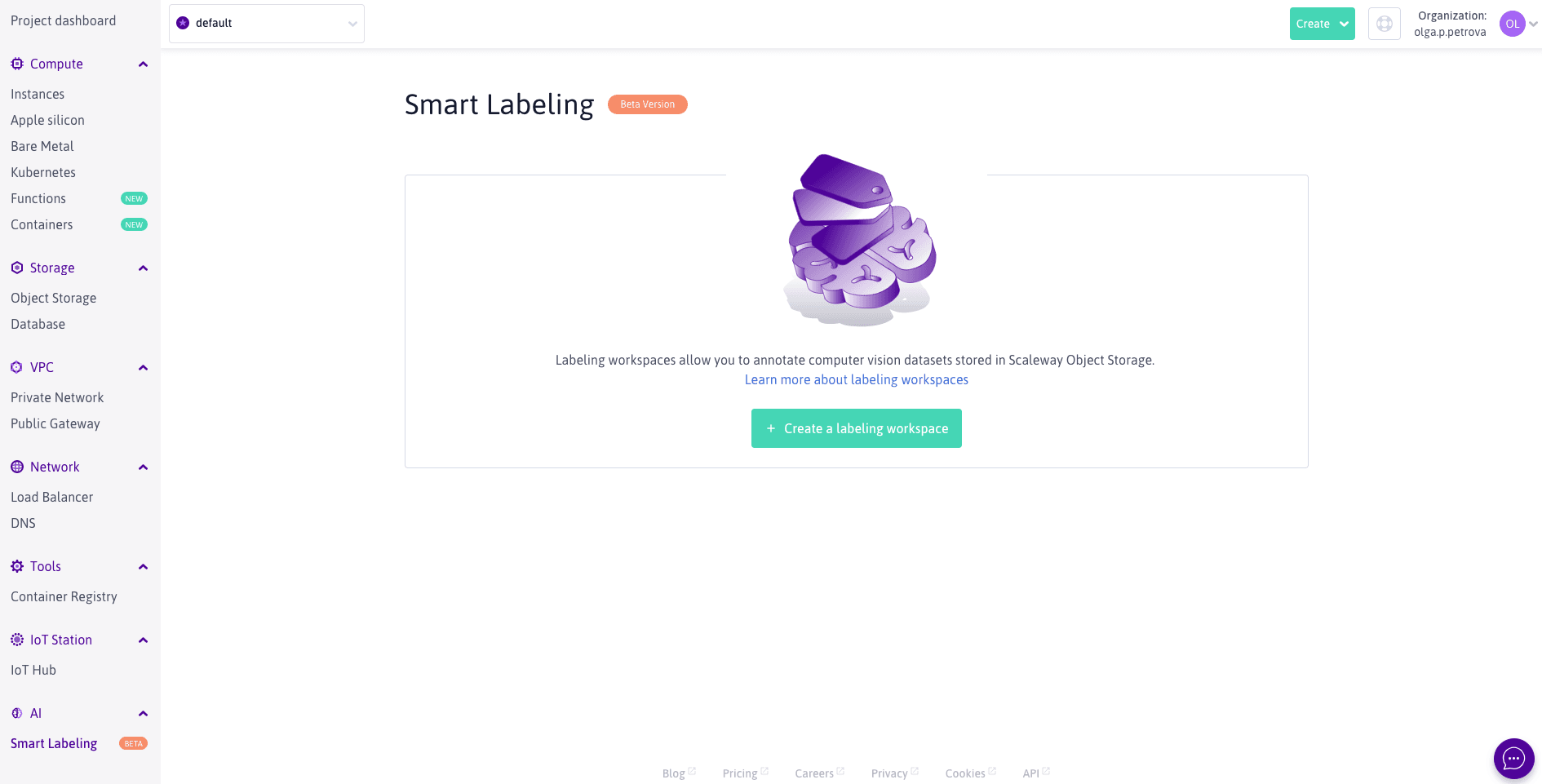
Think of the Labeling Workspace as an area where you can carry out multiple annotation tasks on a dataset of your choice. The annotation interface that Smart Labeling is currently using is that of CVAT: the open-source Computer Vision Annotation Tool developed by Intel. Smart Labeling facilitates using CVAT in the cloud-native manner, with labeling software running on-demand, annotations safely persisted in an automatically backed up database, and datasets stored in cost-efficient Object Storage buckets.
After you fill in the Labeling Workspace name and the optional description, select the bucket(s) that the data that you wish to annotate is located at:
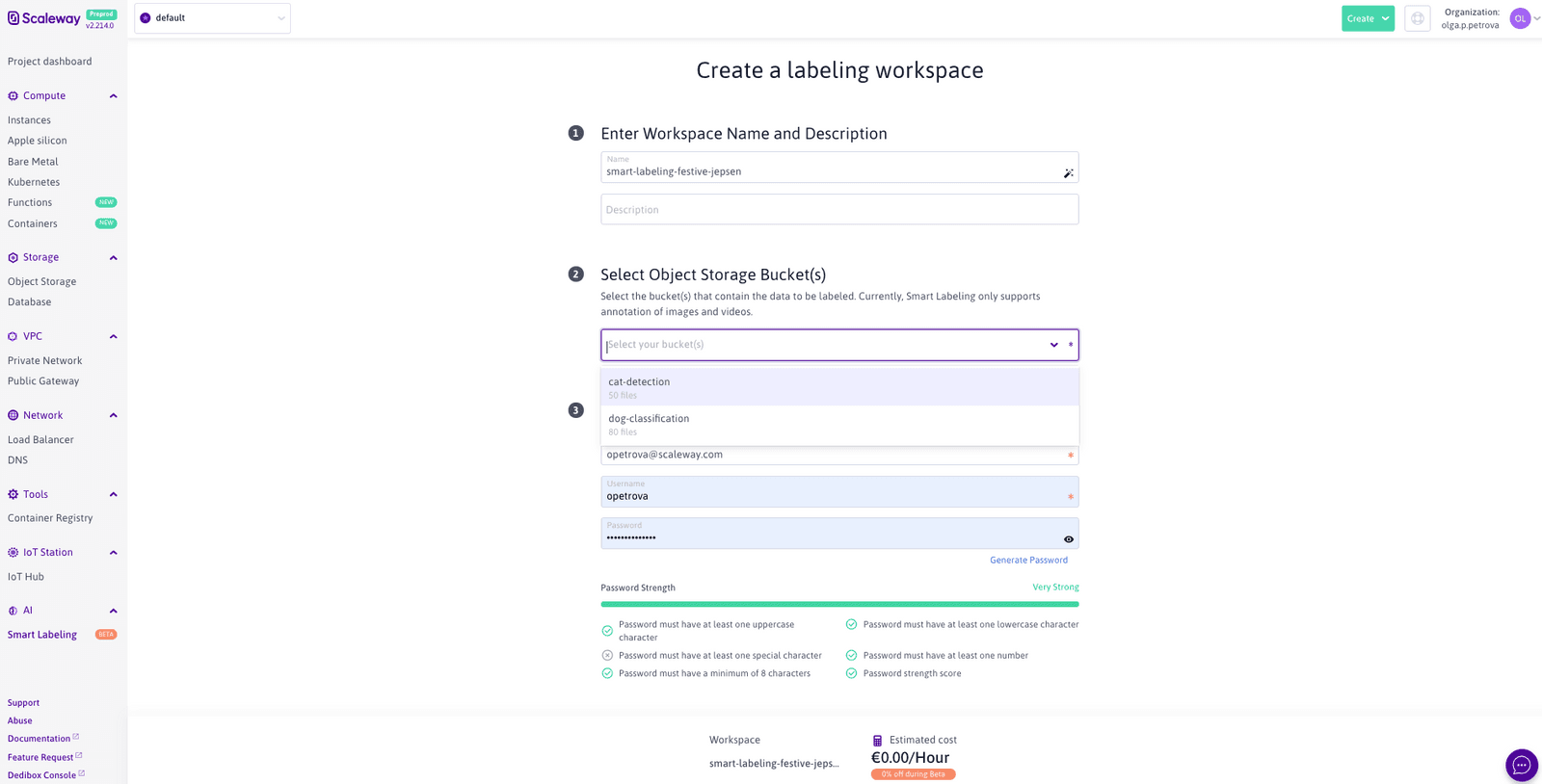
Currently, Smart Labeling only supports the annotation of image and video file formats. If you happen to also have other files stored in the selected buckets, not to worry: you won’t be able to view them in the annotation interface, but their presence will not cause an error in the application.
What remains is to enter the credentials that you, the Admin of this Labeling Workspace, are going to use to log onto the annotation server (accessible outside of the Scaleway console):
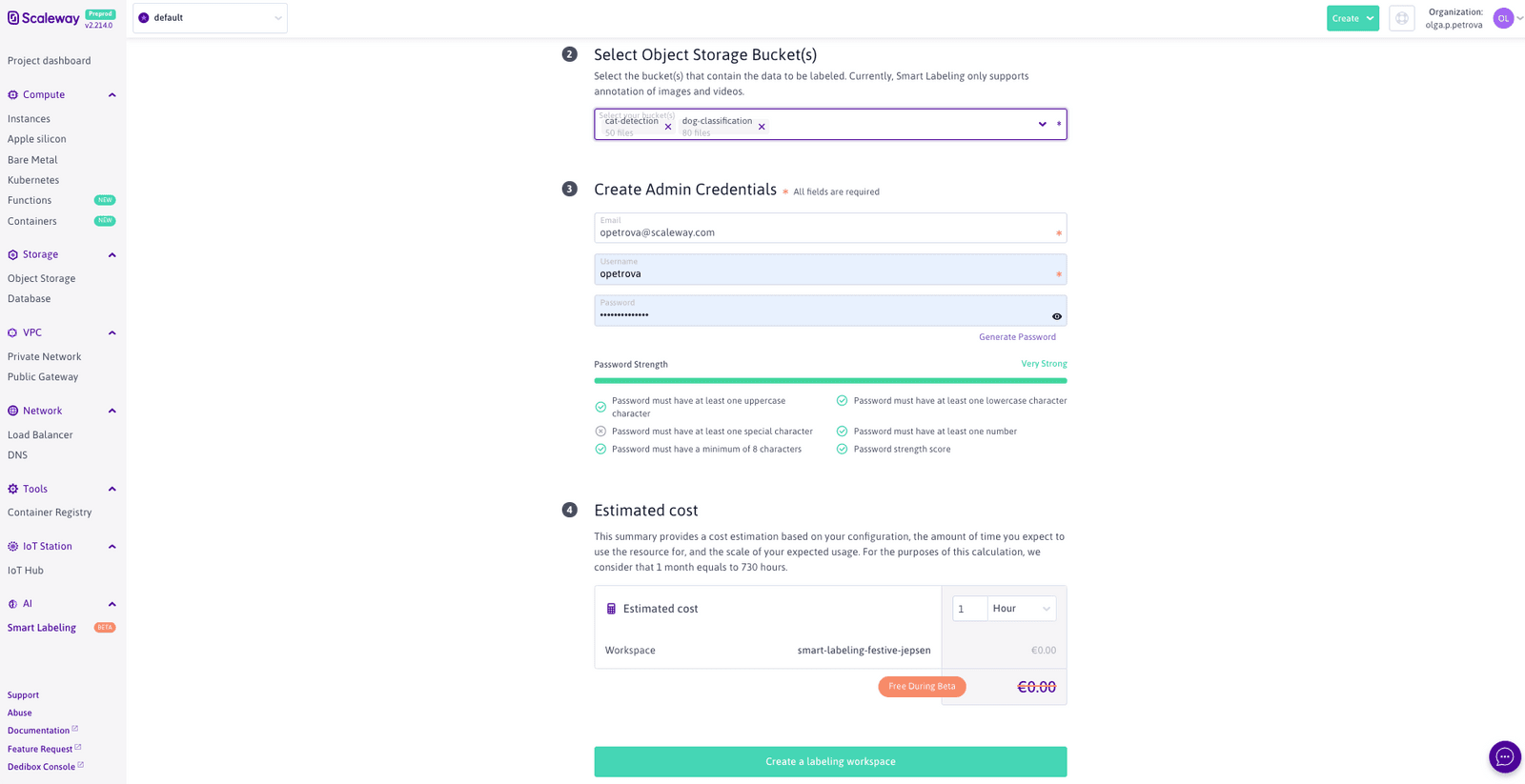
Time to click on the Create button and sit back while we take care of all the pesky setup business for you. You will be taken to the creation page that shows the current progress. Feel free to navigate away from it and check back on the Workspace’s status, by clicking on its name on the Smart Labeling product page:
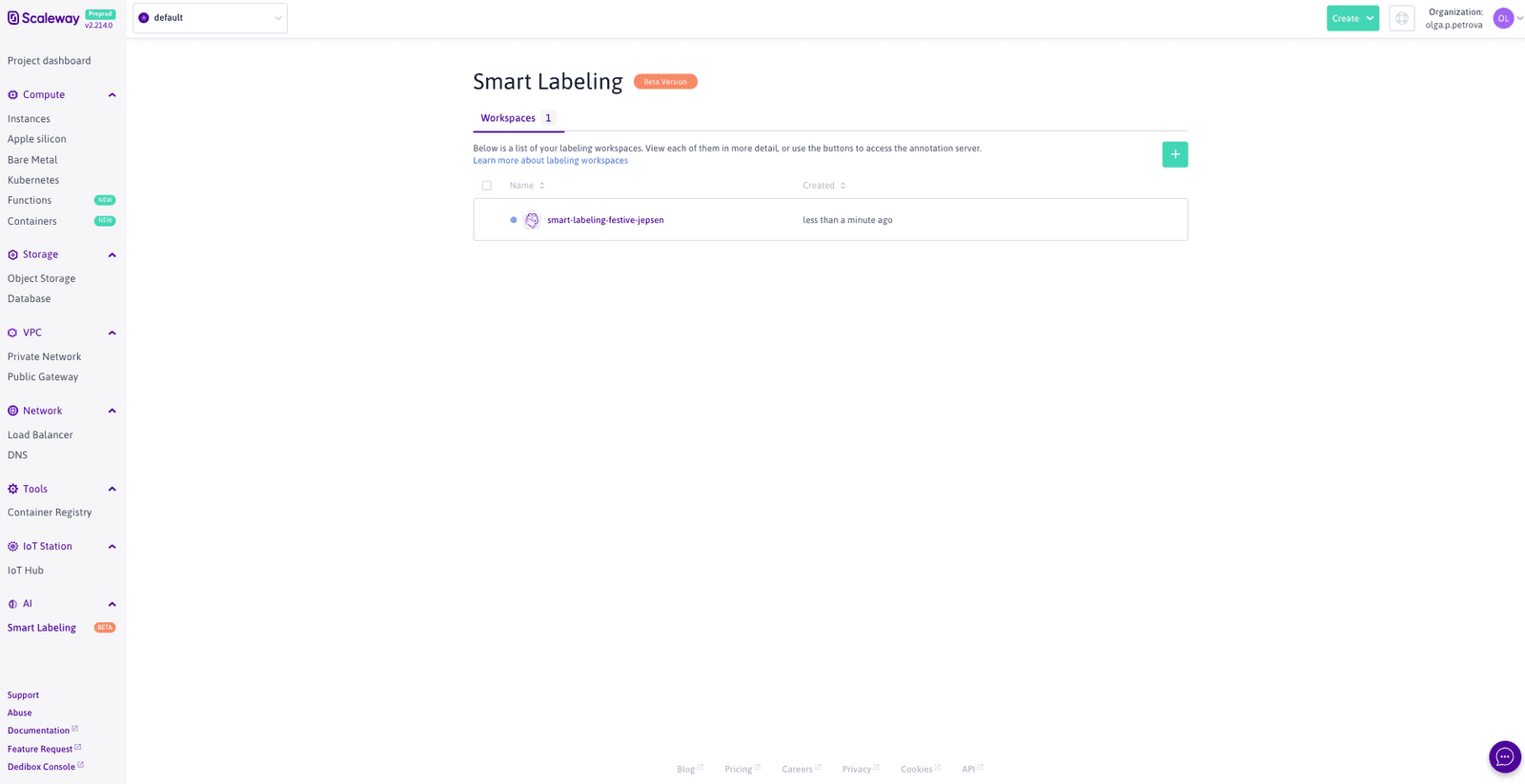
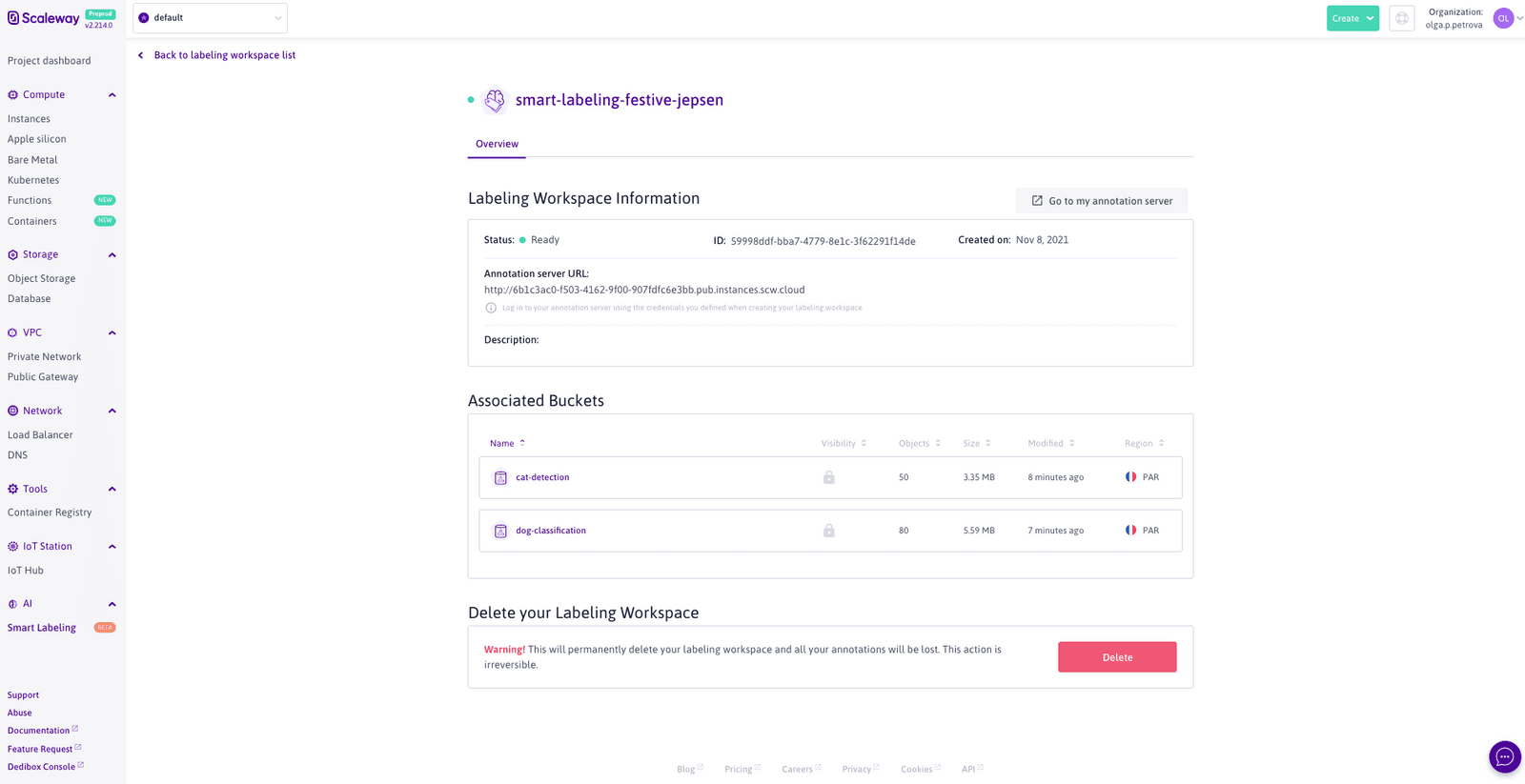
Once your Labeling Workspace has been created (look out for the green “ready” status), you are all set to start annotating: whether on your own or with the help of others (referred to as Annotators, to set them apart from you, the Admin, who can create and delete Labeling Workspaces). Annotators do not need to create Scaleway accounts. All you have to do is share with them the Annotation server url, shown in the Labeling Workspace information block above. This URL will take you (or the Annotator) to the CVAT annotation interface, whose login home page is publicly accessible (meaning that you do not have to go through the Scaleway console once you make note of this link). Here the Annotator can create a new CVAT account. Although the Annotator can immediately use the account to log into the annotation server, they won’t have access to the annotation tasks you have created, unless you assign the task to them, or you change their permissions by going into the Django administration panel of the CVAT server. You can access the latter by clicking on your username in the upper right corner of the CVAT screen and selecting Admin page out of the dropdown menu that appears.
Note that what CVAT refers to as the superuser, who has full access to the Django administration panel of the annotation server, is the same person as the Admin of the Labeling Workspace. Simply use the credentials that you entered while creating the Labeling Workspace to login into CVAT and you are set to go.
When you (or a verified Annotator, depending on what permissions you assigned to her), log into your Labeling Workspace’s annotation server, you will arrive at the CVAT home screen. Here you will be able to create Tasks to annotate datasets of your choice with image-level tags, as well as points, bounding boxes, polygons, and 3D boxes. When creating a new Task, the data from the Object Storage buckets associated with your Labeling Workspace is readily available under the Connected file share tab:
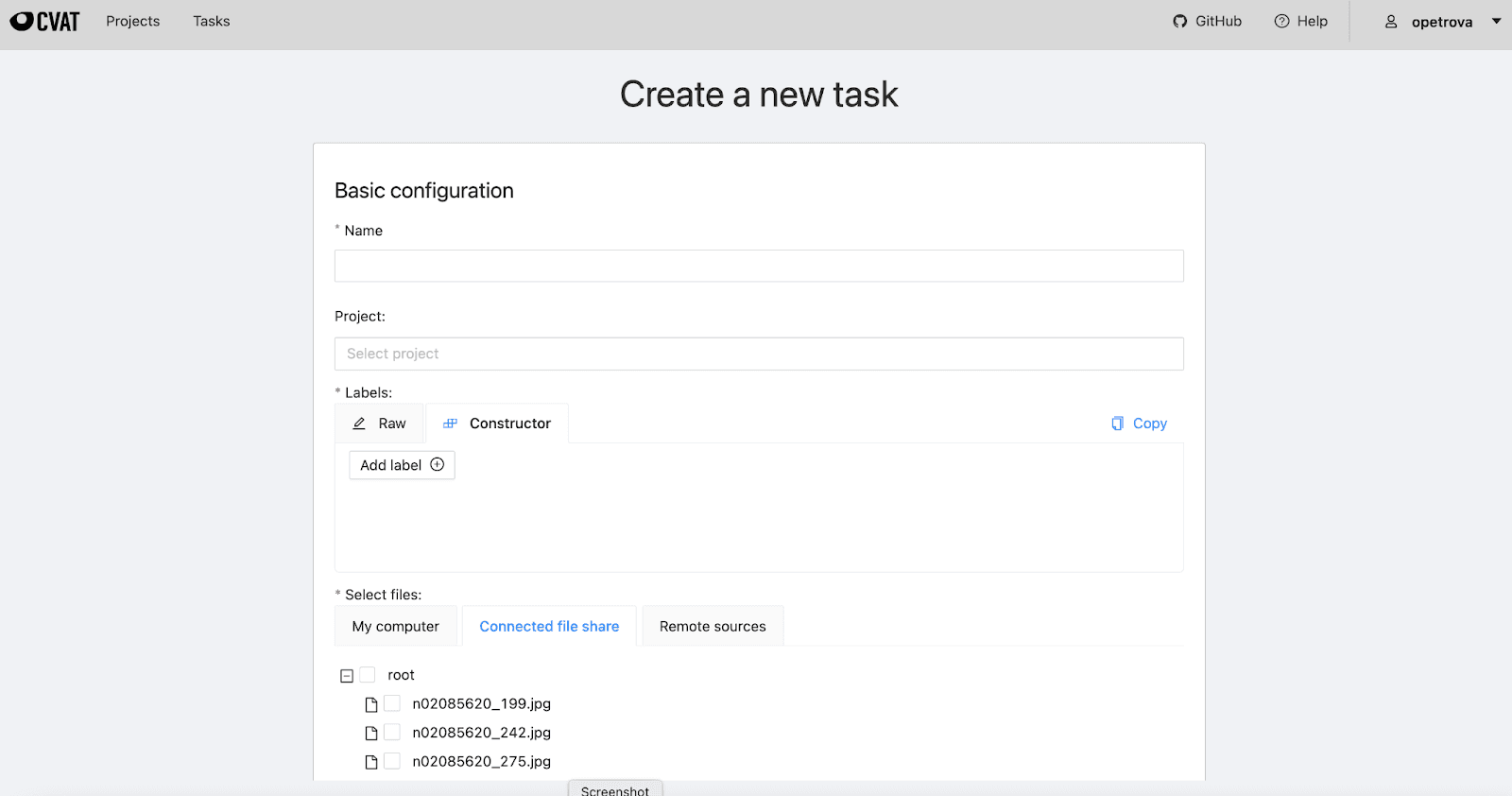
Now that you have the means to label your data, let’s look at some of the information that you might want to note down in addition to the labels that the machine learning model will be trained to reproduce.
Before we get into this, let me stress that these are additional labels - however, not in the sense that you are adding a set of class labels to your original problem. Rather, you are performing another annotation task in parallel with the original one. To provide you with a toy example, imagine that you are working on dog vs. cat image classification. This is a binary classification problem. If you were to collect additional annotations (examples to be discussed shortly), the machine learning task that you are solving remains that of binary classification, and you would have to take care not to include any labels beyond 0 and 1 as part of the model’s loss function.
Now, what are these mysterious additional labels?
If you have been working in computer vision for a while, you have likely heard the tank detection urban legend. There are several versions of it floating around, usually going something like this: a neural net was trained to recognize photos of Soviet vs. American tanks with near 100% accuracy. Only later did it turn out that the American tanks in the dataset happened to be photographed on sunny days, whereas the Soviet tanks did not (or vice versa, depending on who is telling the story). So what the network learned to do was actually to simply compute the average brightness of the pixels in the photo: not very useful when it comes to tank detection in the wild!
While this particular tank challenge may or may not have taken place, the problem of machine learning models picking out unwanted features during training is all too common. Before you start annotating, take a good look at your data. Do certain classes occur more frequently on photos taken inside or outside? When the object is near the camera or far away? At night or during daylight? Sometimes these conditions may be part of the information that a human expert would use to come up with the ground truth label. E.g. a wolf is more likely to be photographed in the woods than a similar-looking husky is to be pictured at a dog park. The sort of conditions that you want to watch out for is the undesirable artifacts of a limited training set. When in doubt, label them for at least a subset of your data, and use that subset to compose a balanced validation set (balanced when it comes to both target classes and the additional “labels”). If you see that your model yields a higher error rate for a certain condition (or seems to have been trained to detect the wrong feature altogether), you have your work cut out for you.
One special case of the above is particularly important: bias. Unwanted bias is a frustratingly common side effect of using historical training data. Society changes, but the relics of the past remain ingrained in numerical data, photos, videos, audio, and text. Present-day models get trained on this data and are then utilized to make decisions, possibly further perpetuating stereotypes and social injustice. To do your part in breaking this vicious cycle, start by identifying certain protected characteristics (such as race, gender, visible religious affiliation, etc) that the results of your model should not depend on in the real world. Consider some examples:
Newly employed data scientists find that no amount of models and fine-tuning of hyperparameters can make up for the poor quality of their training data...

This article is the first installment of a two-post series on Building a machine reading comprehension system using the latest advances in deep learning for NLP.

In this article we are going to look at how to set up a data annotation platform for image and video files stored in Scaleway object storage, using the open source [CVAT]