AI models are everywhere, but sometimes, even the best LLMs produce bafflingly random outputs. Why? And more importantly—how can you tweak it?
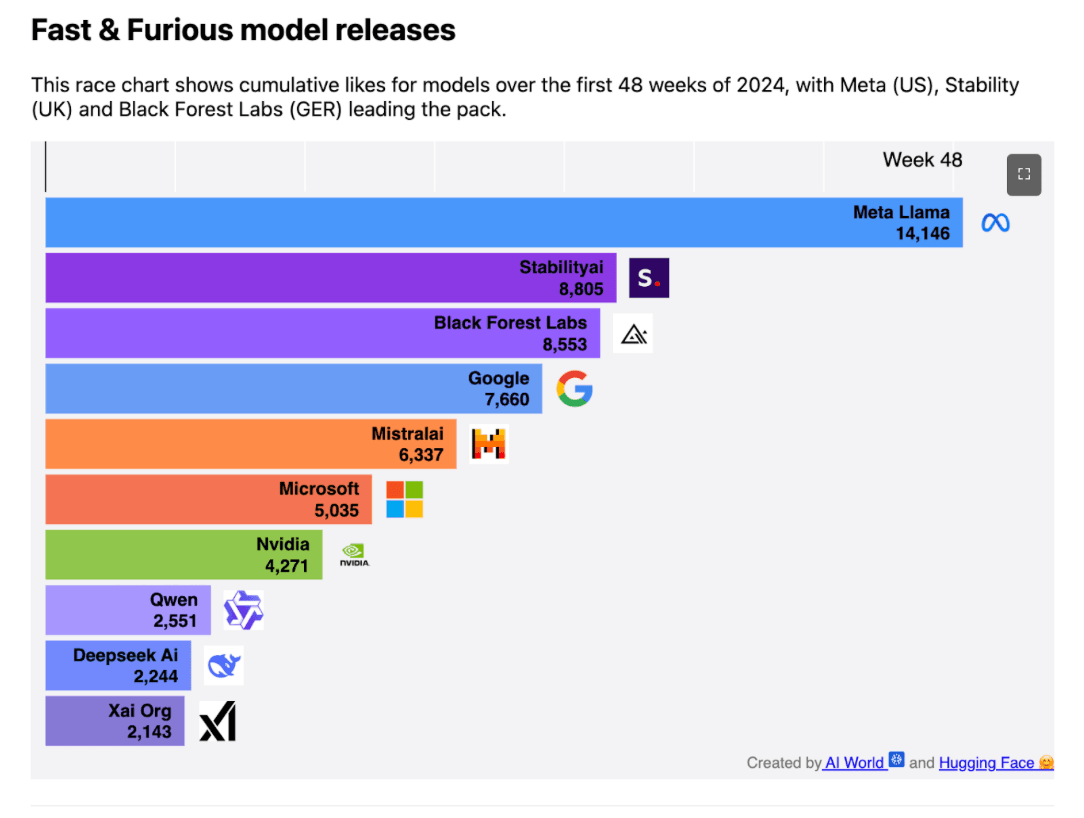
In 2024, the AI landscape has been evolving at breakneck speed. The race to release new models is relentless, with cutting-edge architectures dropping almost weekly. aiworld.eu and Hugging face teamed up to analyze the trends, tracking cumulative likes on models over 48 weeks. The data tells a clear story: the market is moving faster than ever, with new features, optimizations, and surprises constantly reshaping the AI ecosystem.
But with all this innovation comes confusion. AI models and the APIs that run them are still quite new for a lot of people and their usage can sometimes be puzzling.
Why do AI models sometimes behave unpredictably? How can you regain control? And finally, how can you ensure model accuracy at scale?
Let’s break it down.
Why do AI models sometimes behave unpredictably?
One of the biggest surprises? LLMs aren’t built to be fully deterministic. That means, even for simple questions like “1+1=?”, you might get unexpected variations. This isn’t a bug—it’s a feature. Some applications thrive on creative responses, while others demand strict, repeatable outputs. LLMs have not been built to be deterministic as any other algorithms, there are many use cases for which we want the LLM to generate creative answers and many others for which we look for a clear deterministic answer
Regain control: how to get deterministic outputs for a model?
Adjust the determinism of the model:
- Temperature: put the temperature at 0, which is the equivalent to tell the LLM to stop being creative.
- Seed: provide a fixed seed, force the 1st tokens to be something you determine. If you provide this seed and temperature is 0, then the tokens that follow will always be the same
While LLMs can generate random lists of words without meaning or grammatical structure, this output is generally not useful. The ideal “creativity level” is something in between completely deterministic and completely random. This can be adjusted through:
- Temperature: put the temperature at 0.7. Overall values between 0.5 and 1 will add different levels of randomness. Values above 1 should usually be avoided, as they will usually output completely random words after a few paragraphs (even mixing languages).
- Top P: Set up a high top p (eg. above 0.7). This value influences the diversity of output, which is equivalent for the model to have a wider vocabulary. As an example, if you ask the model “List 10 known but original colors”, the model will provide:
Colors like “Mocha” or “Lavender” with a top_p of 0.01, because these words are widely used overall in the language.
Previous colors, and additional ones like “Amber”, “Taupe”, “Caramel”, “Cobalt” with a top_p of 1, which are less frequent in english language
- Prompts: Besides changing typical LLM settings, you can also engineer your prompts directly, to guide the LLM to provide original outputs. Sometimes adding prompts such as “Provide creative outputs” is enough to change a lot of results.
Want to take control of your LLM’s randomness? Play around with different models and settings on Generative APIs. Your first million tokens are free. Experiment, tweak, and see the difference for yourself.
Be careful—modifications can have unpredictable impacts at scale. Whether you're tweaking your model for more deterministic output, adjusting prompts for accuracy in a specific feature, or relying on a model builder who may be deprecating or modifying the model without your knowledge, it's crucial to validate changes. You need to check the accuracy of modifications at your application level, as they can introduce hidden bugs in your workflow that may only surface in certain use cases.
Model accuracy at scale: how to ensure a different LLM version or configuration will not break my application?
Setting up an AI application (whether it’s a Chatbot or a RAG- based (Retrieval-augmented generation) Agent) usually requires a lot of effort at all steps of the life cycle: prompt engineering, RAG pipelines retrieval accuracy, function calling trigger sensitivity, manual testing…
Performing all these steps again with a newer LLM version can be tedious but is necessary to avoid regressions in your application.
Indeed, there are usually no guarantees that a newer LLM version (even a minor one) or configuration will provide the same output quality for all prompts on all thematics.
However, you can still limit the risk by:
- Using models which are fine-tuned versions of the previous model you were using. Similar output is not fully guaranteed, but will usually differ less than a completely different model.
- Setup automated testing pipelines on sample dataset:
- Based on LLM classification (also known as “LLM as a judge”): you can ask an LLM (the same one, or a bigger and thus more accurate one) to classify the quality of the output. This solution is not perfect, but can help detect many issues preventively.
- Based on strict / rule-based verification: if the output of the LLM can be verified with simple algorithms, you should definitely implement these checks. This can be done either with:
- Raw outputs (eg. text), such as code. If your LLM generates code, you can try running this code, and if it doesn’t work, you know for sure the output is incorrect.
- Structured outputs (eg. json output), such as structured representation of the content or intent. For instance, if you try to digitize and process a picture of a bill, you should use structured outputs, and have the LLM output each line of the bill and the corresponding total. You can then check if the total matches the sum of all the lines. Again if your total doesn’t match, you know for sure you cannot trust the output.
Note that in both cases, the checks performed will only ensure the content may be correct (as in “looks plausible”). There is no 100% guarantee the content is correct (eg. in the code example, the code may run, but without doing what you expected). Since by design, LLMs provide “plausible” outputs you should be particularly careful of this. Models can indeed easily create hallucinations which appear consistent (eg. in the billing example, total bill lines may match, but one line may have been modified to compensate for an error in another one).
- Perform manual testing at scale: Many applications developers still choose to perform A/B tests on users samples. Although this can take some time and be costly, it is the most reliable way to avoid regressions on a wide variety of usage.
Although advances in generative AI continue to push the boundaries of what’s possible, they also raise significant concerns about the reliability of models and the accuracy of their outputs. LLM hallucinations, far from being simple technical glitches, serve as a reminder that these systems are not oracles of truth. Additionally, they highlight how these models can reflect and perpetuate biases present in the training data.
As AI becomes increasingly integrated into decision-making processes, projects must take into account the ethical implications in the response error rate of these technologies. To address these concerns, research-driven initiatives such as prompt analysis and model testing are emerging, aimed at making AI more explainable. Learn in our next article how we can identify and mitigate biases in AI outputs, ultimately working toward more reliable and fair responses.