Versatile usage
Leveraging efficient and fast image and video decoding, rendering, as well as Deep Learning model training and inference, the L4 GPU Instance covers a versatile range of needs.
Maximize your AI infrastructure's potential with a versatile and cost-effective GPU Instance

Leveraging efficient and fast image and video decoding, rendering, as well as Deep Learning model training and inference, the L4 GPU Instance covers a versatile range of needs.
Offering a cost-effective alternative to higher-priced GPUs, the L4 GPU Instance achieves solid performance without burdening restricted budgets, enabling startups and small-scale projects.
L4 GPU Instance delivers excellent video generation, decoding, and pre-post processing, empowering industries like fashion, architecture, gaming, and advertising with coherent visual content creation.
DC5 is one of Europe's greenest data centers, powered entirely by renewable wind and hydro energy (GO-certified) and cooled with ultra-efficient free and adiabatic cooling. With a PUE of 1.16 (vs. the 1.55 industry average), it slashes energy use by 30% compared to traditional data centers.
GPU
NVIDIA L4 Tensor Core GPU
GPU Memory
24GB GDDR6 (300 GB/s)
Processor
8 vCPUs AMD EPYC 7413
Processor frequency
2.65 Ghz
Memory
48 GB of RAM
Memory type
DDR4
Network Bandwidth
2.5 Gbps
Storage
Block Storage
Cores
Tensor Cores 4th generation RT Cores 3rd generation

Secure an exclusive pricing to build a cost-effective inference infrastructure at €0.75/h/GPU
If you’ve put a text-to-image model in production, and you’re looking to optimize the cost of you’re infrastructure but not at the cost of performance. L4 Instance GPU is a serious candidate.
L4 GPU Instance generates a 256x256px image in 14445.1 pixel/second
And with 50 percent more memory capacity, L4 enables larger image generation, up to 1024x768, which wasn’t possible on the previous GPU generation (T4)
Source: Model tested InvokeAI a popular open-source framework for image generation and modifications. On top of it Cloud Mercato created invokeai-benchmark, a handy tool make our tests and methodology more easily reproducible.
L4 GPU Instance is the next secret tools of any teams working in:
Manufacturing, automotive industry
GPUs like the NVIDIA L4 GPU empowers design and engineering teams with real-time simulations for early evaluation of 3D models. These life-like simulations accelerate analysis, enable teams to quickly test viable design modifications and modify models before final validation, resulting in an acceleration of product creation.
Gaming, Content creation industry
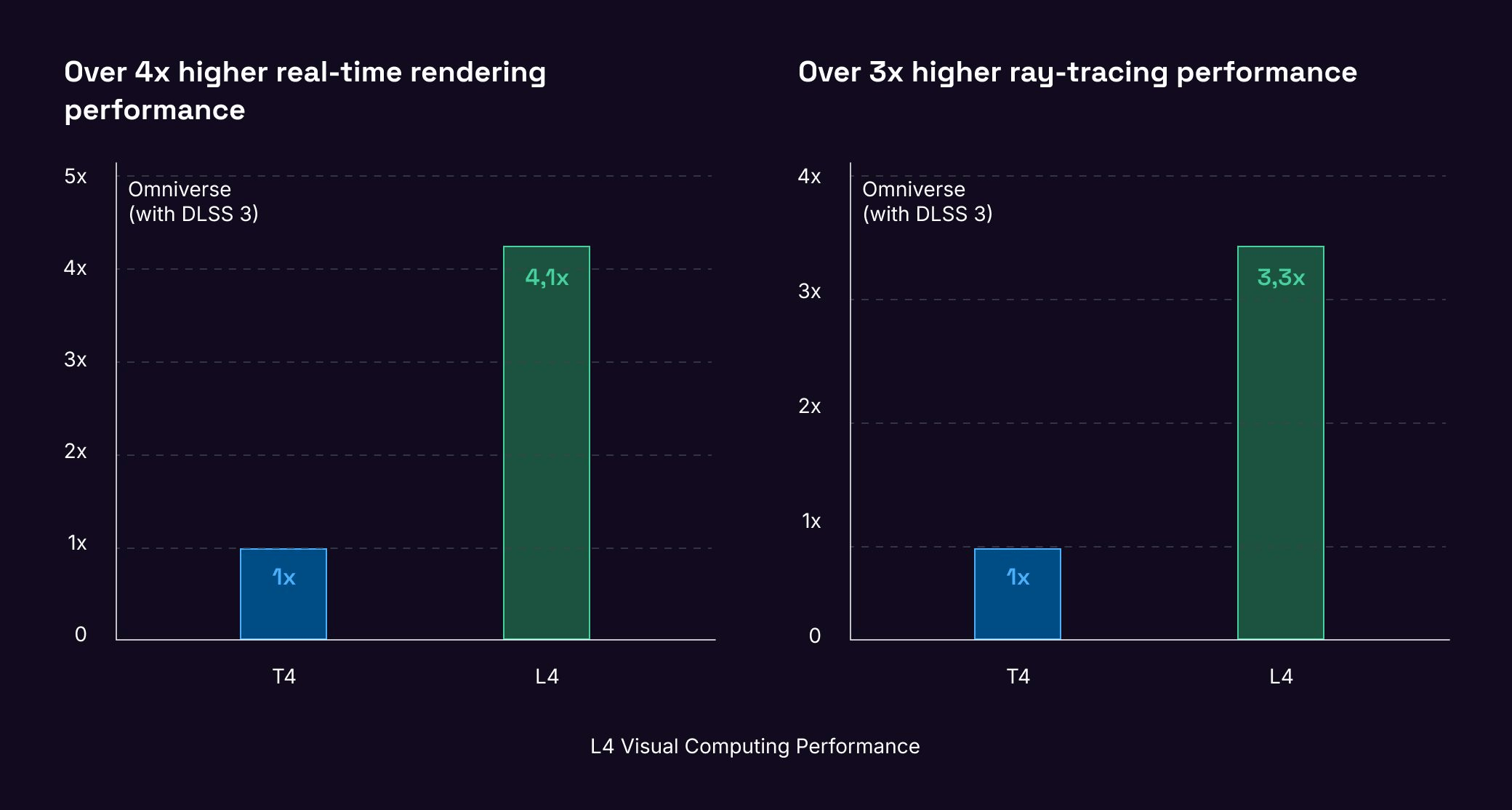
L4 GPU Instance can also empower creators to build real-time, cinematic-quality graphics and scenes for immersive visual experiences, thanks to its brand new third-generation RT Cores.
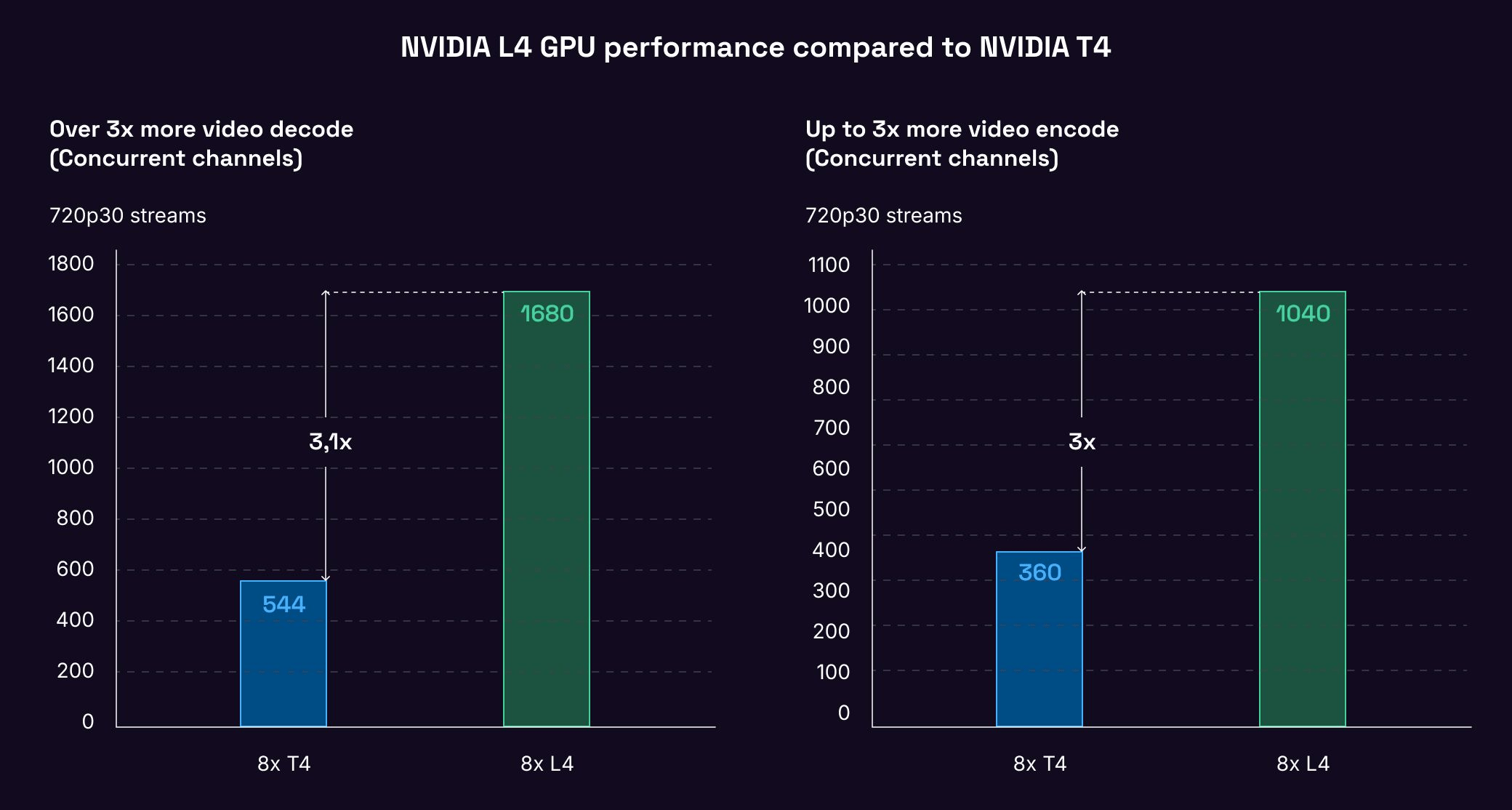
With up to 3x the H264 video encoding and decoding performance of the T4, and 120x the performance of CPU-based solutions, the L4 is the ideal choice for real-time AI video pipelines.
The L4 GPU Instance is capable of hosting over 1,000 AV1 video streams at 720p30 for mobile applications, and with fourth-generation Tensor Core technology and FP8 precision support, it takes video content understanding to a new level.
Plus, with up to 120x better energy efficiency and cost of ownership compared to traditional CPU-based infrastructure, the L4 GPU Instance is not only powerful but also cost-effective.
_Source: NVIDIA_
| Option and value | Price |
|---|---|
| ZoneParis 2 | |
| Instance1x | 0€ |
| Volume10GB | 0€ |
| Flexible IPv4No | 0€ |
| TotalEnergy | Price |
|---|---|
| Hourly 0 kgCO2e≈ 0 km by car | 0€ |
| Daily 0 kgCO2e≈ 0 km by car | 0€ |
| Weekly 0 kgCO2e≈ 0 km by car | 0€ |
| Monthly 0 kgCO2e≈ 0 km by car | 0€ |
Choose your Instance's format
With four flexible formats, including 1, 2, 4, and 8 GPU options, you can now easily scale your infrastructure according to your specific requirements.
| Instance Name | Number of GPU | TFLOPs FP16 Tensor Cores | VRAM | price per hour | price per minute |
|---|---|---|---|---|---|
| L4-1-24G | 1 NVIDIA L4 Tensor Core GPU | 242 TFLOPS | 24GB | €0.75/hour | €0.0125/min |
| L4-2-24G | 2 NVIDIA L4 Tensor Core GPU | 484 TFLOPS | 2 x 24GB | €1.5/hour | €0.025/min |
| L4-4-24G | 4 NVIDIA L4 Tensor Core GPU | 968 TFLOPS | 4x 24GB | €3/hour | €0.05/min |
| L4-8-24G | 8 NVIDIA L4 Tensor Core GPU | 1936 TFLOPS | 8x 24GB | €6/hour | €0.1/min |


Monitor your infrastructure and applications in real-time with a fully managed observability solution.

Match any growth of resource needs effortlessly with an easy-to-use managed Kubernetes compatible with a dedicated control plane for high-performance container management.

Distribute workloads across multiple servers with Load Balancer to ensure continued availability and avoid servers being overloaded.

Secure your cloud resources with ease on a resilient regional network.
Our GPU Instances' prices include the vCPU and RAM needed for optimal performance.
To launch the L4 GPU Instance you will need to provision a minimum of Block Storage and a flexible IP at your expense.
Any doubt about the price, use the calculator, it's made for it!
These are 4 formats of the same instance embedding NVIDIA L4 Tensor Core GPU.
NVIDIA Multi-Instance GPU (MIG) is a technology introduced by NVIDIA to enhance the utilization and flexibility of their data center GPUs, specifically designed for virtualization and multi-tenant environments. This features is available on H100 PCIe GPU Instance but not on the L4 GPU Instance. However users can benefit from Kubernetes Kapsule compatibility to optimize their infrastructure.
There are many criteria to take into account to choose the right GPU instance:
For more guidance read the dedicated documentation on that topic