
Amener du trafic vers vos pods avec Load Balancer
L'aspect mise en réseau est l'un des plus complexes de Kubernetes. Pour pouvoir proposer un service publiquement accessible et réussi dans Kubernetes, il faut savoir comment leverager les bons outils

Dans le contexte économique actuel, l'agilité et l'amélioration continue sont des moteurs essentiels de la réussite. Chaque organisation, quelle que soit sa mission, s'appuie sur un socle technologique solide, de plus en plus renforcé par les solutions d'intelligence artificielle (IA).
Acteur de référence sur le marché français, Golem.ai propose une gamme de produits, dont le fer de lance est Inboxcare, destinée à optimiser la relation client des entreprises en intégrant des modèles d'IA pour assurer un traitement rapide et efficace des messages entrants.
En tant que client de Scaleway Cloud, l'infrastructure de Golem.ai repose sur des services gérés, notamment Kubernetes et des bases de données gérées. Kubernetes, comme le soulignent les récents rapports de la communauté DoK, s'est imposé comme un outil clé pour l'intégration des solutions d'IA, grâce à ses capacités avancées d'orchestration des charges de travail et à l'automatisation des pipelines CI/CD. En optimisant le cycle de vie des conteneurs, au cœur de cet écosystème, Kubernetes permet une gestion des ressources efficace et performante.
Dans cet article, nous explorons une méthode mise en œuvre par Golem.ai pour optimiser l'espace disque sur Kapsule, la solution de cluster Kubernetes gérée par Scaleway. Cette pratique est basée sur une gestion intelligente des images dans le système sous-jacent, qui fonctionne avec le runtime Containerd, et sert de recommandation précieuse pour améliorer la gestion des ressources dans les environnements conteneurisés.
Pour rappel, les utilisateurs de Kapsule ont un accès direct au système de fichiers, mais il n'est pas recommandé de le manipuler, par exemple en se connectant au nœud via SSH. Il est également important de considérer que, pour l'accélération des performances et du démarrage des applications, notamment dans le cadre de l'Horizontal Pod Autoscaling grâce à l'utilisation de KEDA, le runtime du conteneur utilisera en priorité les images déjà présentes dans le cache plutôt que de les télécharger depuis un registre des conteneurs. Cette solution est également bénéfique pour augmenter la disponibilité des images en cas d'incident dans le registre des conteneurs.
Mais que faire des images qui restent stockées sur un nœud et qui occupent progressivement un pourcentage important de l'espace disque ?
Une option pourrait être d'augmenter l'espace disque des nœuds de stockage par bloc pour stocker plus d'images. Cependant, cette solution entraînerait des coûts supplémentaires et des risques opérationnels pour l'environnement de production de Golem.ai, tout cela pour héberger des images obsolètes et inutiles.
Chez Golem.ai, la gestion du cycle de vie des images sur les nœuds est automatisée grâce à un processus qui répertorie et supprime les images inutilisées après une certaine période. Ce processus interagit directement avec le runtime du conteneur, Containerd, à partir d'un pod, comme illustré dans cet article. Son objectif est de suivre le rythme rapide des déploiements, avec plusieurs versions de production par jour, qui consomment plusieurs gigaoctets de stockage dans nos différents environnements.
Cette approche de gestion du cycle de vie permet de libérer de l'espace disque, d'éviter la saturation des nœuds, d'optimiser l'utilisation des ressources et de réduire le coût du cloud, à la fois budgétaire et environnemental, en réduisant l'empreinte carbone - un défi courant dans la gestion des clusters.
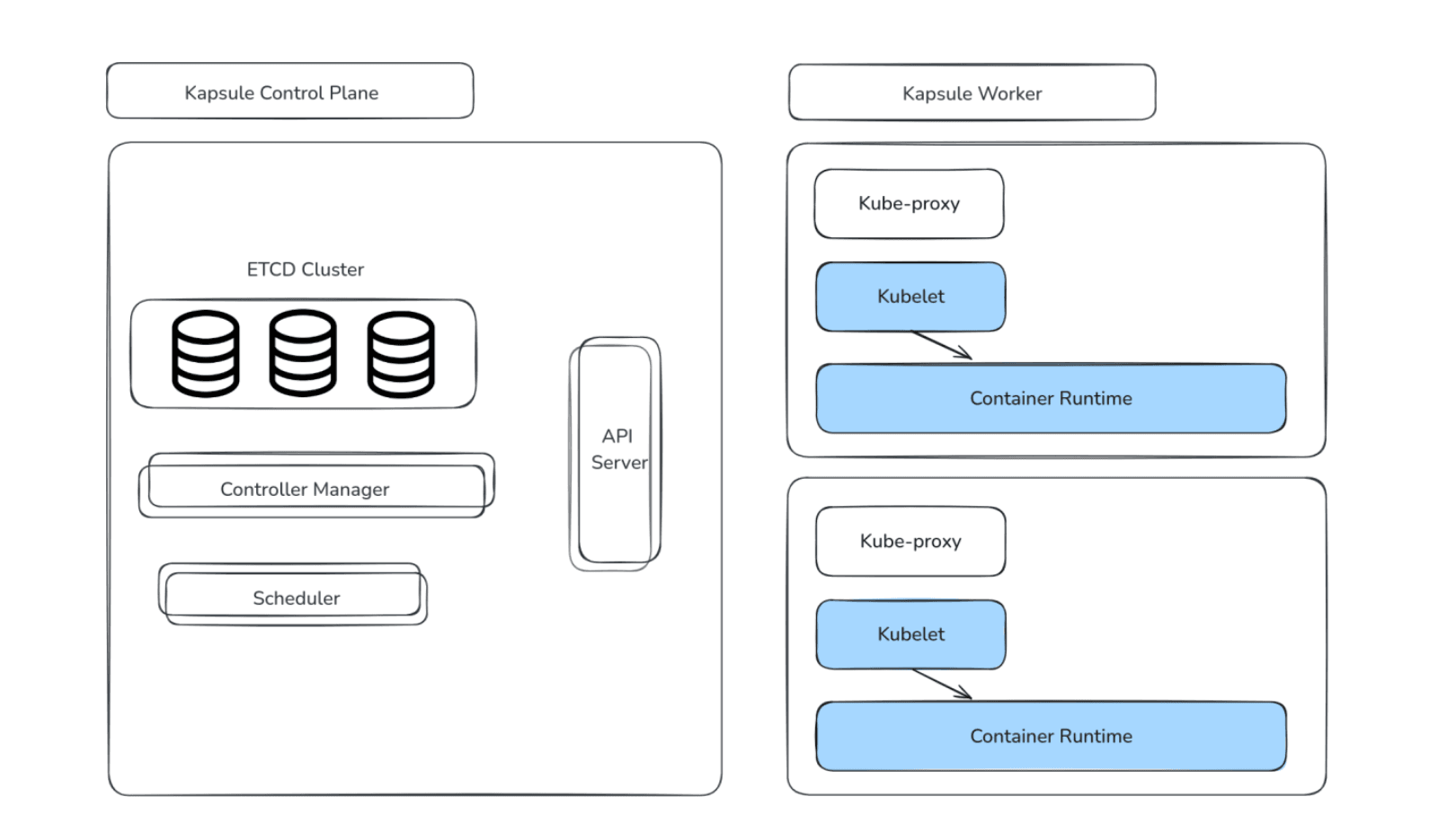
Voici un aperçu d'un cluster Kapsule, composé du plan de contrôle (Master) et des nœuds (Workers) sur lesquels les charges de travail sont exécutées.
Le moteur d'exécution du conteneur (Containerd) utilisé par Golem.ai sur les nœuds de travail de Kapsule applique un processus d'analyse des images et de suppression de celles qui ne sont pas conformes à la politique de cycle de vie.
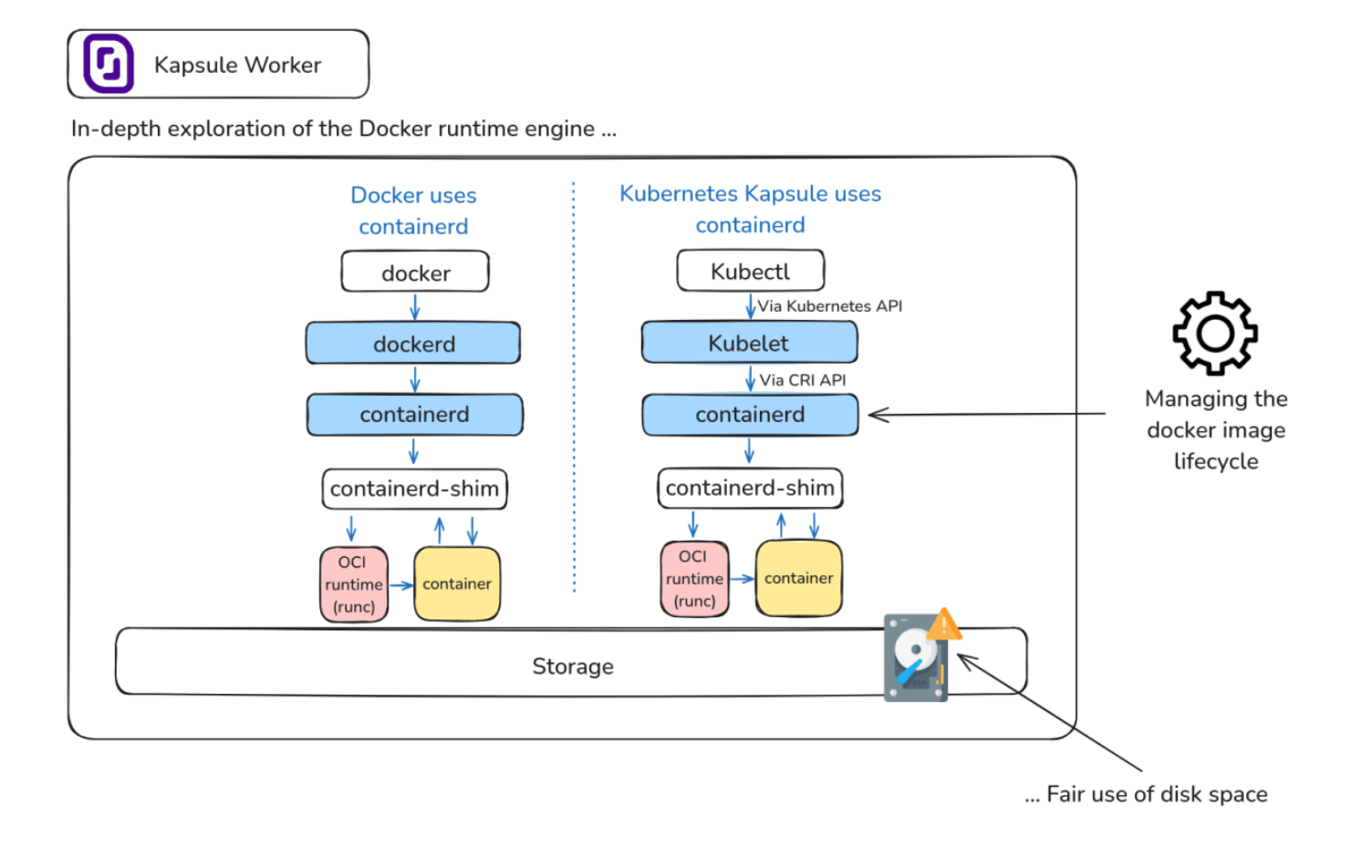
Pendant le scan effectué chaque jour à minuit, le processus de nettoyage de Golem.ai supprime toutes les images inutilisées qui ont été créées il y a plus de 30 jours[1].
Cette opération ne s'applique qu'aux images du GitLab Registry de Golem.ai ou du backup Registry créé sur Scaleway Registry, qui sert de solution de repli en cas de défaillance du GitLab Registry.
Pour ce faire, le processus de nettoyage utilise un volume monté dans le pod exécutant le scan, avec le chemin sur l'hôte correspondant au socket Containerd runtime, ainsi que deux variables d'environnement configurées pour permettre au crictl CLI, de communiquer avec ce socket monté.
volumes: - name: containerd hostPath: path: /var/run/containerd/containerd.sock type: Socket -------- env: - name: CONTAINER_RUNTIME_ENDPOINT value: unix:///var/run/containerd/containerd.sock - name: IMAGE_SERVICE_ENDPOINT value: unix:///var/run/containerd/containerd.sock volumeMounts:https://kubernetes.io/docs/concepts/architecture/garbage-collection/#containers-images- name: containerd mountPath: /var/run/containerd/containerd.sock La tâche récurrente s'exécute tous les jours à minuit sur tous les nœuds des différents pools de clusters, à l'aide d'un DaemonSet configuré avec un ConfigMap pour configurer correctement le travail Cron.
apiVersion: v1 kind: ConfigMap metadata: name: imgcleanupcjcm namespace: ops-tools labels: component: imgcleanup data: # Removing unused images from registry.gitlab.com/golem-ai or rg.fr-par.scw.cloud, which is 30 days old. cronjobs: 0 0 * * * cd /tmp/ && bash imgcleanupscript.sh L'ensemble de la configuration est disponible sur le GitHub public de Golem.ai.
https://github.com/golem-ai/clean-docker-image-kapsule-scaleway
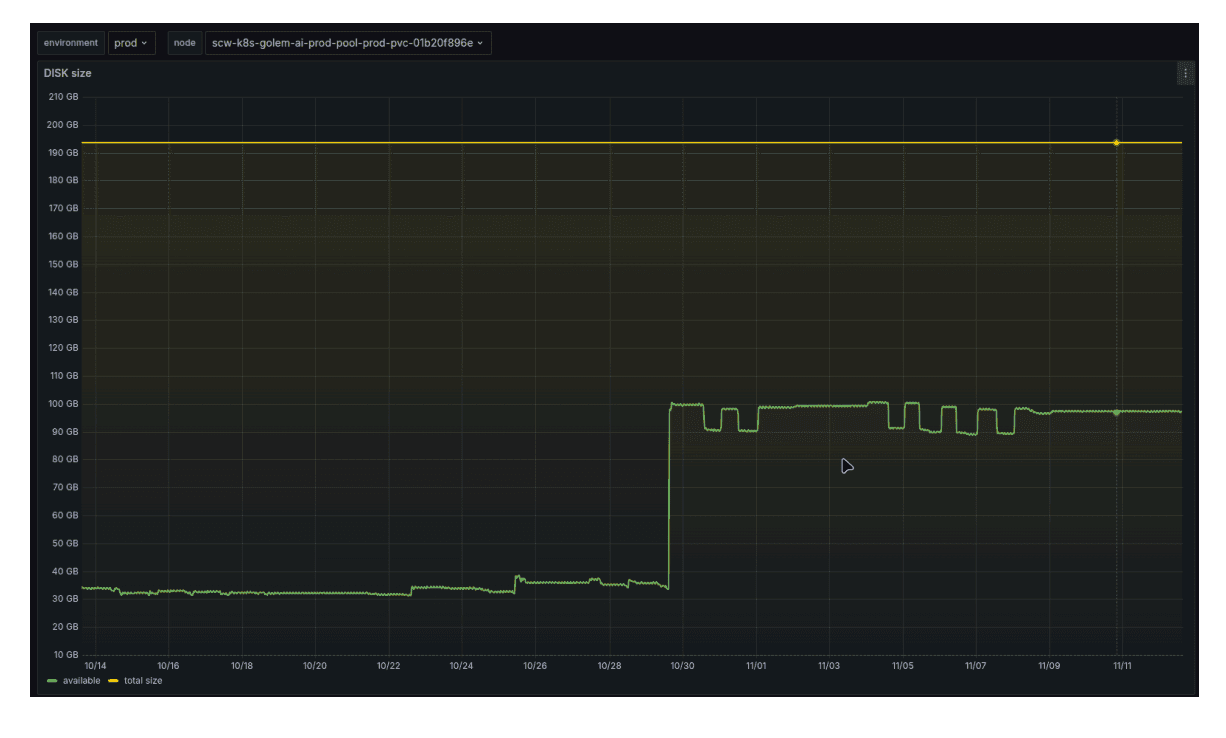
Une multiplication par trois de l'espace de stockage disponible sur les machines de production et de préproduction, sans impact sur le traitement du flux de travail du client : comme le montre l'image ci-dessus, marquée par la ligne verte, l'augmentation de l'espace disque est d'environ 250 Go pour toutes les machines de production et de 350 Go pour les machines de préproduction.
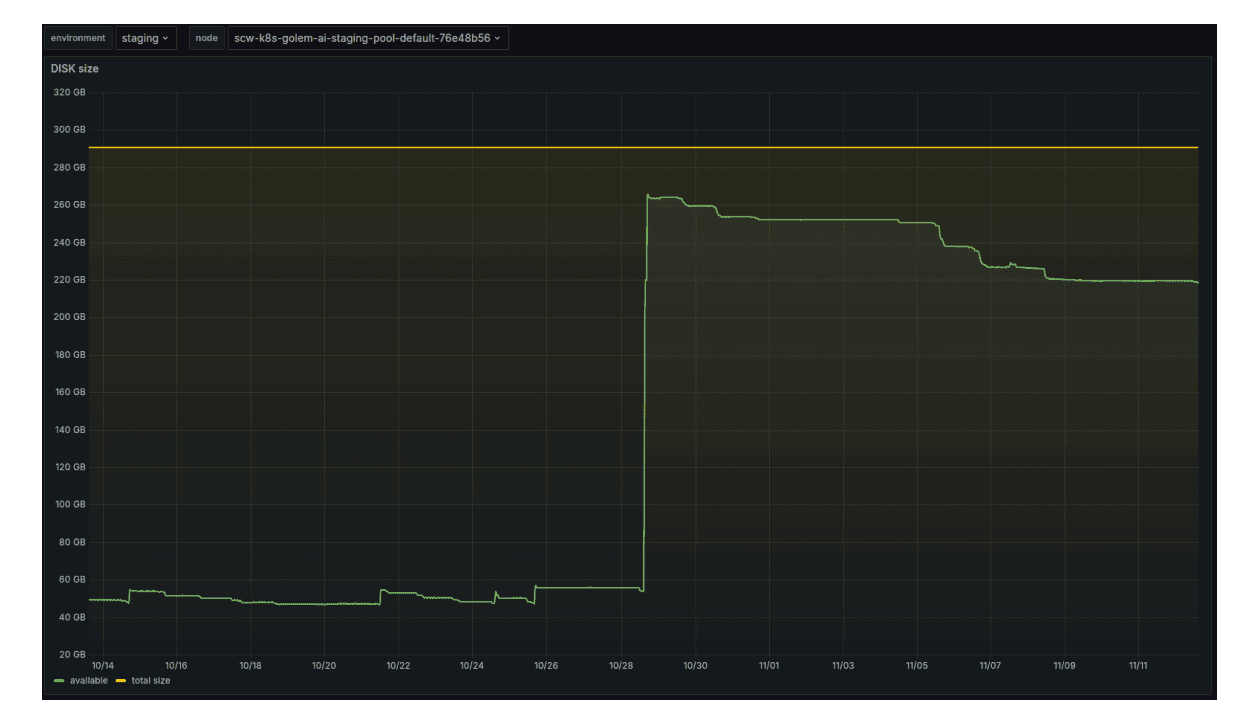
Dans l'environnement Staging, le résultat est encore plus visible, avec une multiplication par quatre de l'espace de stockage libéré (image ci-dessous), ce qui permet de libérer environ 1 To d'espace disque sur l'ensemble des machines de staging.
Golem.ai bénéficie d'un système O&M (Operational Maintenance) automatisé, conçu pour servir efficacement ses clients et ses équipes de développement. Ce système permet de réaliser d'importantes économies de temps et d'argent sur l'ensemble de la chaîne de valeur, tout en garantissant un traitement optimal des flux de travail de ses clients.
L'approche décrite dans cet article est basée sur des pratiques rigoureusement développées visant à maximiser la performance et l'efficacité - des éléments clés pour les solutions d'IA. Elle répond non seulement aux besoins des entreprises à la recherche d'infrastructures performantes, mais s'inscrit également dans un engagement plus large en faveur de la durabilité et de la responsabilité.
Pour en savoir plus :
Forsgren, Nicole, Jez Humble et Gene Kim, Accelerate : The Science of Lean Software and DevOps : Building and Scaling High Performing Technology Organizations. IT Revolution Press, 2018.
Data on Kubernetes 2024 : Beyond Databases : Kubernetes as an AI Foundation, Rapport de recherche, novembre 2024.
Francisco Javier Campos Zabala, Grow Your Business with AI : A First Principles Approach for Scaling Artificial Intelligence in the Enterprise, Apress 2023.
[1] La méthode proposée dans cet article est complémentaire et ne fait pas partie du processus de nettoyage par défaut de Kubelet. A la date de publication de cet article, aucune version stable de Kubelet ne permet de configurer le nettoyage des images de conteneurs en fonction de leur date de création ou de leur registre d'origine. Source
L'aspect mise en réseau est l'un des plus complexes de Kubernetes. Pour pouvoir proposer un service publiquement accessible et réussi dans Kubernetes, il faut savoir comment leverager les bons outils

Vous pouvez désormais profiter de notre control plane managé et haute disponibilité pour créer vos clusters de conteneurs. Découvrez Kubernetes Kapsule dans cet article
Dans cet article, nous allons distinguer les différentes méthodes d'autoscaling fournies par Kubernetes et comprendre les différences entre l'horizontal pod autoscaler et le vertical pod autoscaler.