
Comment protégeons-nous vos données ?
Suite aux événements récents, vous êtes très nombreux à nous interroger sur nos pratiques et nos moyens de protection dans nos datacenters. Nous allons vous répondre avec un maximum de transparence.

Cet article a été rédigé par l'association Infoclimat dans le cadre de notre nouvelle série Give Me The Pen qui prête la plume de notre blog aux organisations de notre communauté.
Nous sommes ravis d'accueillir Frédéric Ameye, bénévole, vice-président de l'association Infoclimat et responsable de l'infrastructure et du site web https://www.infoclimat.fr/ depuis 2009 pour nous présenter l'historique des choix techniques et les challenges associés à leur évolution.

Infoclimat tire ses origines d’un groupe de passionnés qui a vu à la fin des années 90 l’intérêt du réseau Internet pour partager ses données météo au plus grand nombre : relevés météo, photographies, phénomènes dangereux,...
Principalement porté par un site Internet, l’initiative a grossi jusqu’à nécessiter des moyens informatiques importants et des coûts de bande passante exponentiels, nécessitant en 2003 la création d’une association loi 1901.
Aujourd’hui, l’association a un budget annuel de quasi 60.000€, 1800 adhérents, et s’auto-finance entièrement. Elle installe ses propres stations météo, réalise des actions pédagogiques sur le terrain et avec les établissements scolaires, et contribue à l’établissement d’un commun numérique, par l’ouverture de ses données.
C’est un peu comme OpenStreetMap ou Wikipédia, mais pour la météo !

À l’époque, nous avions une dizaine de stations météo qui reportaient une donnée par heure.
Aujourd’hui, nous récoltons les données de 30.000 stations météo de part le monde, qui reportent toutes les demi-heures ou dix minutes, nous avons des algorithmes d’interpolation sophistiqués, des cartographies interactives, 6 milliards d’entrées dans nos bases de données, et des Téraoctets de cartographies. Sans compter un forum de discussion à 3.5 millions de messages, et un trafic annuel de 6 à 7 millions de visiteurs uniques.
Nos bases de données (MySQL) supportent un bon millier de requêtes par seconde, et il en va de même pour nos serveurs web (NGINX).
Et pour exploiter au mieux toutes ces données météo, nous utilisons massivement des serveurs de cartographie (mapserver) et de nombreux codes de calcul scientifique qui sont assez intensifs en CPU et en accès disques, des moteurs de recherche (Elastic/Sphinx) et bien évidemment de nombreuses couches de cache applicatif (memcached/Redis).
Notre site a une réputation dans la qualité des données affichées, mais aussi dans le confort de navigation. Nous n’avons pas de publicités ou de trackers, c’est un choix de notre part, et nous veillons à ce que nos pages soient efficaces au chargement, malgré la quantité de données et la complexité des interfaces (graphiques, cartographies). Nous souhaitons le moins possible reposer sur des services externes qui pourraient disparaître du jour au lendemain (et en 20 ans, on en a vu !), et ainsi assurer la pérennité de nos données.
La sécurité et la sûreté de nos données nous tient beaucoup à cœur : la masse de données météo collectée et contrôlée minutieusement par nos bénévoles est inestimable, et nous portons une grande attention aux données personnelles de nos adhérents et visiteurs.
De 2004 à 2015, nous gérions nos machines en “bare metal”, à la main, ce qui nécessitait un investissement bénévole toujours plus conséquent.
En 2015, nous sommes passés à une solution “Dedicated Cloud” de notre hébergeur historique OVH, pour remplacer nos dix serveurs dédiés. L’objectif : quitte à payer un peu plus cher, simplifier la gestion pour les bénévoles en charge de l’infra. La solution était basée sur VMWare vSphere, et, à performances égales, devait coûter environ 1.5x plus cher que nos machines bare-metal, mais avec une bien meilleure aisance dans la gestion.
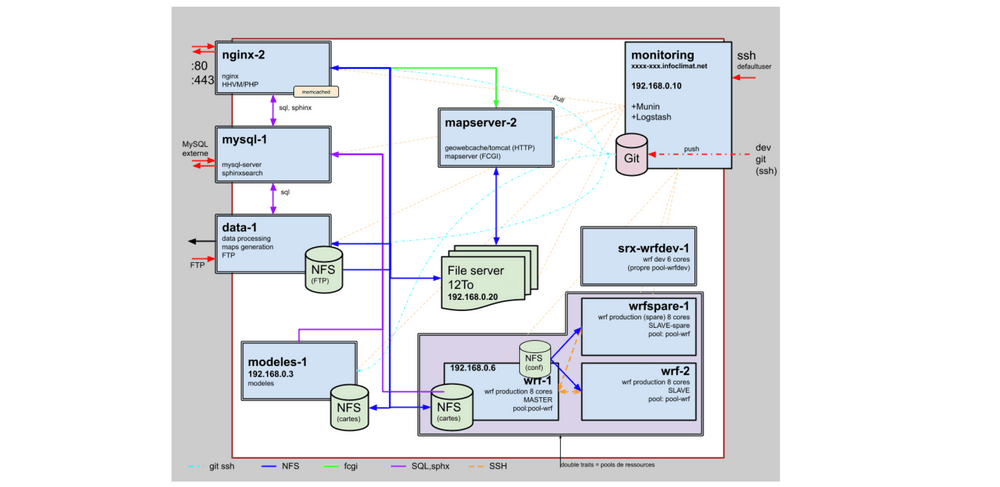
L'image ci-dessus montre notre architecture de 2006, qui était basée sur des machines placées sur un “cloud dédié” à base de vSphere. La solution coûtait quelques milliers d’euros par mois à l’association, et quelques cheveux blancs par semaine à l’auteur de cet article.
Nous avons été assez échaudés par cette solution : après une très longue migration, les performances n’étaient pas acceptables, le site web était souvent en panne, et nous avons eu quelques corruptions de machines virtuelles et de bases de données qui nous ont donné de grosses nuits blanches et des pertes de données. Nous avons découvert quelques bugs de l’hyperviseur qui ont été corrigés par le fournisseur et ont stabilisé la situation, nous avons aussi appliqué d’énormes optimisations dans nos applications, mais le constat était clair : la solution n’était pas assez performante, et aurait nécessité un coût 2 à 3x plus important qu’avant pour être suffisamment stable.
En 2016, nous avons dit stop à cette solution, et sommes repartis sur des machines dédiées, avec les idées un peu plus claires sur les erreurs à ne pas refaire.

L'architecture de 2020 ci dessus était axée sur l’aspect “stockage”. Les flux applicatifs ne sont pas représentés, mais représentent environ ¼ de machines pour le back-end (NGINX, PHP), ¼ de machines de calcul (modèles météo, générations de cartographies), ¼ de machines de stockage (bases de données et serveurs de fichiers), et ¼ de machines spécialisées (serveurs de tuiles, caches, moteurs de recherche).
En particulier, nous avons toujours un peu “buté” sur le stockage de nos volumineux contenus (cartographies mondiales, photos,...), et avons évolué progressivement. Pendant quelques années, nous avons administré notre propre cluster GlusterFS. C’était très satisfaisant dans l’utilisation, la scalabilité et la sûreté des données, mais la gestion était très complexe, à cause d’un parc de serveurs hétérogène (versions de Debian, et donc versions du protocole GlusterFS). Nous sommes revenus à une solution plus simple, à savoir un unique serveur de fichiers - cela est cependant plus risqué.
À l’avenir, nous souhaiterions basculer vers une solution plus résiliente, mais cela nécessite d’importants travaux sur notre base de code existante (plus de 400.000 lignes de code).
Depuis toujours, nous avons apporté un grand soin à nos backups, qui étaient chiffrés puis envoyés sur des espaces de stockage fournis par notre hébergeur. Nous étions bloqués par la taille limitée de ces espaces, qui rendaient les backups compliqués à gérer. Avec les téraoctets qui s'accumulent, c’est vite devenu bloquant et stressant.
Nous avons commencé par mettre en place un NAS chez un de nos administrateurs fibré, pour effectuer une sauvegarde “à froid”, chiffrée, de tous nos contenus (une trentaine de téraoctets aujourd’hui).
En 2021, nous avons comme beaucoup d’acteurs revu un peu notre stratégie, et avons compris qu’avoir tous ses œufs dans le même panier n’était pas une bonne idée, et avons cherché d’autres hébergeurs chez qui nous pourrions stocker nos backups, avec une grande flexibilité dans l’espace de stockage.
La solution d’Object Storage de Scaleway nous a paru la plus pertinente : nous avons éliminé d’office tout acteur des GAFAM, et souhaitions un hébergeur français, pour coller à nos valeurs historiques.
Pour ce faire, nous utilisons Duplicity et Rclone pour gérer nos sauvegardes incrémentales sur différents buckets Object Storage, et gérer finement le cycle de vie de nos sauvegardes. On dort l’esprit bien plus tranquille depuis cette mise en place !
La totalité de l’infrastructure chez nos deux hébergeurs nous coûte environ 15.000€ par an, en hausse régulière face à l’augmentation du nombre de données hébergées et les fonctionnalités toujours plus poussées !
Nous avons depuis longtemps la volonté de tirer parti du meilleur des technos : les serveurs dédiés pour les processus sensibles où les performances sont critiques, mais pouvoir être flexibles dans la gestion du stockage et de la charge (et donc du budget). Aujourd’hui, notre volonté est de basculer progressivement dans un mode “hybride”, pour ajuster au mieux les coûts, et surtout simplifier la gestion, le déploiement, et la montée en charge.
Nous avons donc commencé à expérimenter l’interfaçage de notre infra existante avec une infra chez un autre provider, Gandi, pour autre chose que des backups :
Aujourd’hui, nous souhaiterions aller encore plus loin, cependant, nous sommes bloqués par notre caractère bénévole : une seule personne s’occupe sur son temps libre de toute l’infra et de tout le développement depuis plus de 13 ans, et elle n’a pas la capacité d’aller plus loin. Pour cette raison, cette année nous recrutons notre premier salarié : un dév full-stack PHP/JS !
Nous espérons bien recruter un DevOps pour nous aider à rendre notre architecture plus scalable, facilement déployable dans un contexte multi cloud, et rendre open-source tout ça, tout comme nos données sont Open-Data !
Avec cette personne, nous aimerions :
Aujourd’hui, l’association cherche à recruter des salariés, pour accompagner le développement d’une telle infrastructure, ce qui demande un apport financier colossal pour une petite structure comme la nôtre — et grâce à nos adhérents et donateurs, nous allons y arriver !
Nous cherchons à diversifier nos soutiens et sources de revenus, pour assurer une stabilité dans la durée, nous invitons tous les acteurs de la tech’ à nous y aider, par exemple par des actions de mécénat financier, matériel ou de compétences
Évidemment, les développeurs, DevOps, infographistes et autres Data Scientists ou Cloud Architects sont les bienvenus pour nous aider dans cette tâche, à titre bénévole ou salarié selon nos ouvertures de postes.
Suite aux événements récents, vous êtes très nombreux à nous interroger sur nos pratiques et nos moyens de protection dans nos datacenters. Nous allons vous répondre avec un maximum de transparence.

La plateforme Jamespot a été développée sur une architecture monolithique reposant sur des VM. Apprenez comment ils ont migré sur une stratégie multi-cloud.

Familink a récemment migré l’intégralité de son infrastructure d’AWS à Scaleway. Apprenez de leur retour d'expérience comment stocker vos données en Europe.