
Comment Jamespot fait face à la montée en charge grâce à l’adoption du multi-cloud
La plateforme Jamespot a été développée sur une architecture monolithique reposant sur des VM. Apprenez comment ils ont migré sur une stratégie multi-cloud.

Kubernetes fournit une série de fonctionnalités pour garantir que vos clusters ont la bonne dimension pour pouvoir gérer n'importe quel type de charge. Dans cet article, nous allons distinguer les différentes méthodes d'autoscaling (mise à l'échelle automatique en français) fournies par Kubernetes et comprendre les différences entre l'horizontal pod autoscaler, le vertical pod autoscaler et enfin le Kubernetes Nodes autoscaler.
Kubernetes est un outil d'orchestration qui permet aux développeurs de déployer leurs applications le plus sereinement et le plus rapidement possible. Dans une architecture classique, vous devez définir la capacité de votre cluster en vous basant sur la charge estimée générée par vos utilisateurs. Mais imaginez que votre service devient viral, et le nombre de demandes augmente plus vite que vous ne l'imaginiez. Vous risquez de manquer de ressources de calcul, votre service de ralentir et vos utilisateurs d'être frustrés.
Lorsque vous allouez des ressources manuellement, vos temps de réponse peuvent ne pas être aussi rapides que l'exige l'évolution des besoins de votre application. C'est pour répondre à cette problématique que la fonctionnalité Autoscaling de Kubernetes entre en jeu : Kubernetes fournit plusieurs couches de fonctionnalités de mise à l'échelle automatique : mise à l'échelle basée sur le POD avec l'Horizontal Pod Autoscaler et le Vertical Pod Autoscaler, ainsi que basée sur des nœuds avec le Cluster Autoscaler. Il met automatiquement à l'échelle votre cluster dès que vous en avez besoin et redescend à sa taille nominale lorsque la charge est plus faible. Ces couches garantissent que chaque pod et cluster dispose des performances adéquates pour répondre à vos besoins en temps réel!
Dans Kubernetes, un ensemble de machines pour exécuter des applications conteneurisées est appelé Cluster. Un cluster contient au minimum un Control Plane (plan de contrôle en français) et un ou plusieurs nœuds. Le Control Plane conserve l'état souhaité du cluster, par exemple quelles applications s'exécutent sur celui-ci et quelles images il utilise. Les nœuds sont des machines virtuelles ou physiques qui exécutent les applications et les charges de travail, appelées Pods. Les Pods sont constitués de conteneurs qui demandent des ressources de calcul telles que CPU, Mémoire ou même GPU.

Pour plus d'informations sur les différents composants de Kubernetes, consultez notre article de blog : Une introduction à Kubernetes (en anglais)
| Horizontal | Vertical | |
|---|---|---|
| Pod | Ajoute ou retire des pods | Modifie les resources CPU et/ou RAM allouées au pod |
| Node | Ajoute ou retire des nœuds | Modifie les resources CPU et/ou RAM allouées au nœud |
Le Horizontal Pod Autoscaler (HPA) est capable de mettre à l'échelle le nombre de pods disponibles dans un cluster pour pouvoir gérer la charge de travail (ou workload) d'une application. Il détermine le nombre de pods nécessaires en fonction des seuils de ressources que vous avez définies et crée ou supprime des pods basés sur des ensembles de ces seuils. Dans la plupart des cas, ces mesures sont l'utilisation du CPU et de la RAM, mais il est également possible de spécifier vos mesures personnalisées (trafic ou autres). L'HPA vérifie en permanence les mesures de CPU et de mémoire générées par le metrics-server installé sur le cluster Kubernetes.
Si l'un des seuils spécifiés est atteint, l'outil met à jour le nombre de réplicas de pod à l'intérieur du contrôleur de déploiement. Après avoir mis à jour le nombre de réplicas de pod, le contrôleur de déploiement va augmenter ou diminuer le nombre de pods jusqu'à ce que le nombre de réplicas corresponde au nombre souhaité. Si vous souhaitez utiliser des mesures personnalisées pour définir des règles sur la façon dont le HPA gère la mise à l'échelle de vos modules, votre cluster doit être lié à une base de données chronologiques (time-series database) contenant les mesures que vous souhaitez utiliser. Veuillez noter que la mise à l'échelle automatique horizontale des pods ne peut pas être appliquée à des objets qui ne peuvent pas être mis à l'échelle comme, par exemple, les DaemonSets.
Le Vertical Pod Autoscaler (VPA) peut allouer plus (ou moins) de ressources CPU et mémoire aux pods existants afin de modifier les ressources de calcul disponibles pour une application. Cette fonctionnalité peut être utile pour surveiller et ajuster les ressources allouées de chaque pod tout au long de sa durée de vie. Le VPA est livré avec un outil appelé VPA Recommander, qui surveille la consommation actuelle et la consommation passée des ressources. Celui-ci utilise alors ces données pour fournir des valeurs recommandées pour allouer des ressources CPU et mémoire aux conteneurs. Pour rentrer légèrement dans le fonctionnement, le Vertical Pod Autoscaler ne met pas à jour les configurations de ressources pour les pods existants. Il se contente de vérifier si les pods bénéficient d'une bonne allocation des ressources et détruit ceux qui n'ont pas la configuration recommandée afin que leurs contrôleurs puissent les recréer avec la configuration adéquate.
Il est important de noter que si vous voulez utiliser le HPA et le VPA en même temps pour gérer vos ressources de conteneur, il y a de fortes chances pour qu'ils soient en conflit si les mêmes variables utilisées (CPU et mémoire). Les deux essaieront de résoudre la situation simultanément, entraînant une mauvaise affectation des ressources. Cependant, il est possible de les utiliser tous les deux s'ils s'appuient sur des mesures différentes. Le VPA utilise la consommation de CPU et de mémoire comme sources uniques pour recueillir l'allocation parfaite des ressources, mais l'HPA peut être utilisé avec des mesures personnalisées afin que les deux outils puissent être utilisés en parallèle.
L'Autoscaler des nœuds Kubernetes ajoute ou supprime des nœuds dans un cluster en fonction des ressources demandées par l'ensemble des pods. Il est possible de définir un nombre minimum et un nombre maximal de nœuds disponibles pour le cluster à partir de la console Scaleway Elements.
Alors que les autoscalers des pods horizontaux et verticaux vous permettent la mise à l'échelle des pods, l'autoscaler de noeud Kubernetes quant à lui se concentre sur la mise à l'échelle des nœuds de vos clusters. L'outil vérifie s'il y a des pods en attente et augmente la taille du cluster afin que ceux-ci puissent être créés. Il libère également les nœuds inactifs pour garder une taille optimale de votre cluser. Le Node Autoscaler peut demander de déployer de nouveaux nœuds directement dans votre pool (un pool étant un ensemble de nœuds partageant les mêmes configurations), dans les limites de ressources indiquées.
Si des pods sont planifiés pour l'exécution, le Kubernetes Autoscaler peut augmenter le nombre de machines dans le cluster pour éviter le manque de ressources. Le schéma ci-dessous illustre comment un cluster peut être automatiquement mis à l'échelle :
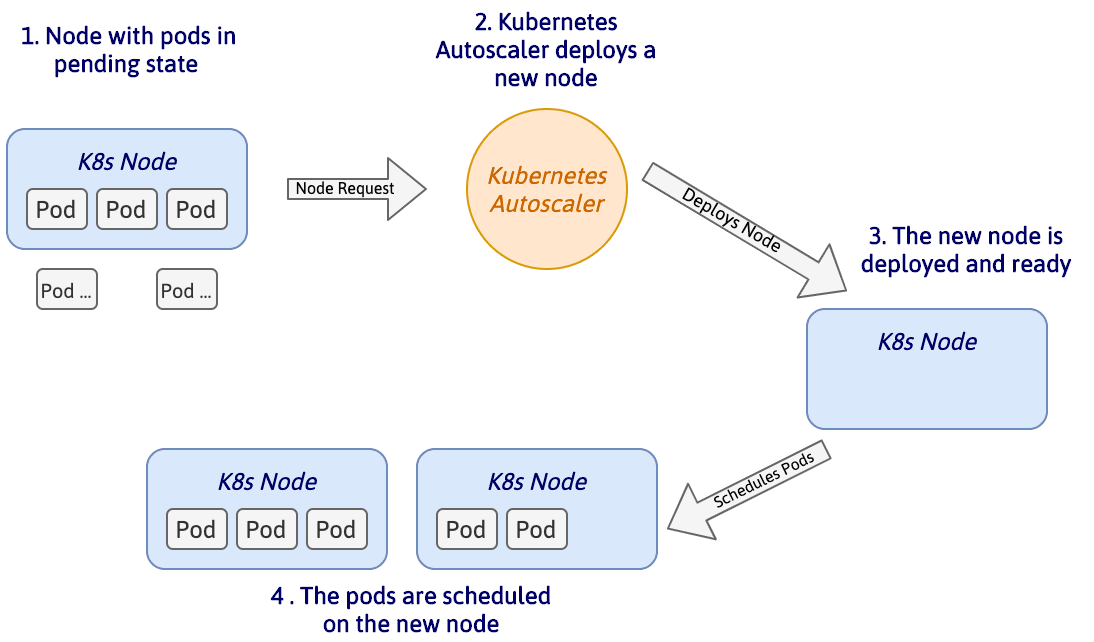
Comme illustré, deux pods sont planifiés pour l'exécution mais la capacité de calcul du nœud actuel est atteinte. L'autoscaler de cluster analyse automatiquement tous les nœuds à la recherche de pods planifiés. Il demande alors l'ajout d'un nouveau nœud si trois conditions sont remplies :
Une fois que le nœud est déployé et détecté par le Control Plan de Kubernetes, le scheduler alloue les pending pods (ou pods en attente en français) au nouveau nœud du cluster. Dans le cas où il y a encore des modules en attente, l'autoscaler répète ces étapes aussi souvent que nécessaire.
Le Kubernetes Cluster Autoscaler diminue le nombre de nœuds dans un cluster lorsque certains sont considérés comme non nécessaires pendant une période prédéfinie. Pour être considéré comme inutile, un nœud doit avoir une faible utilisation, et tous ses modules importants peuvent être déplacés ailleurs sans créer une pénurie de ressources. La vérification de la mise à l'échelle du nœud prend en compte les demandes de ressources faites par les pods, et si le scheduler décide que les pods peuvent être déplacés ailleurs, il supprime le nœud du cluster afin d'optimiser l'utilisation des ressources et de réduire les coûts. Si vous avez défini un nombre minimum de nœuds actifs dans le cluster, l'autoscaler ne réduira pas le nombre de nœuds au-dessous de ce seuil.
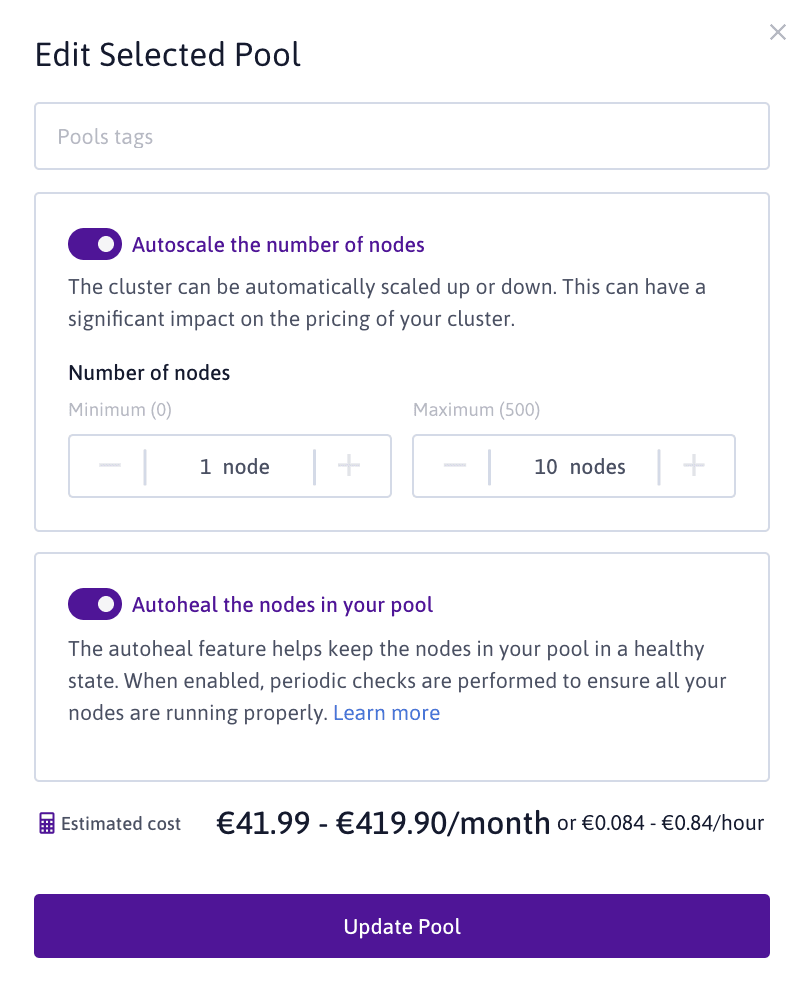
Vous pouvez configurer la mise à l'échelle automatique de cluster directement à partir de la console Scaleway.
Creation d'un nouveau cluster
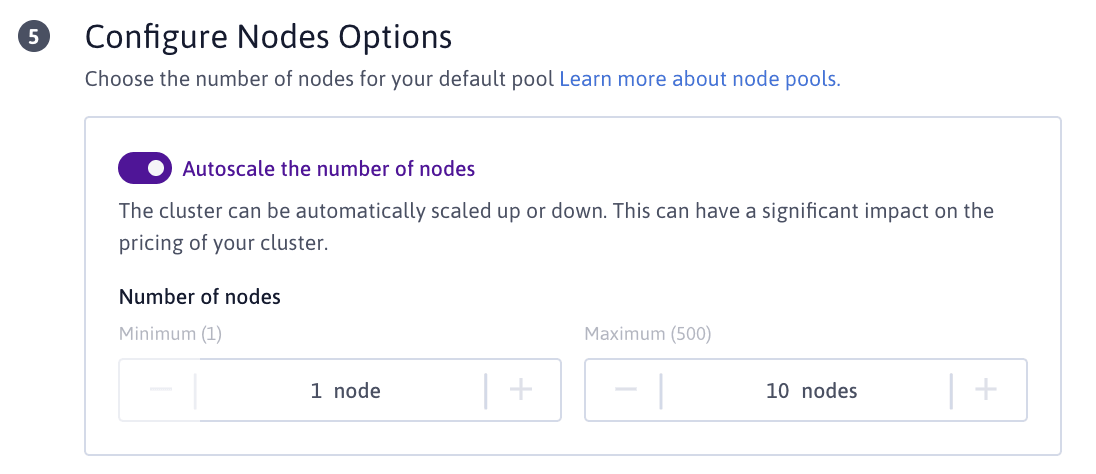
Pour activer Kubernetes Cluster Autoscaling lors de la création d'un nouveau cluster, rendez-vous à l'étape 5, activez le bouton et définissez les ressources minimales et maximales disponibles pour votre cluster :
Vous comprenez maintenant les bases des différentes méthodes d'Autoscaling de Kubernetes et comment vous pouvez les utiliser pour configurer votre cluster pour des performances maximales.
Déployez votre premier cluster Kapsule Kubernetes directement à partir de votre console Scaleway et essayez la fonctionnalité Autoscaling.
La plateforme Jamespot a été développée sur une architecture monolithique reposant sur des VM. Apprenez comment ils ont migré sur une stratégie multi-cloud.

Familink a récemment migré l’intégralité de son infrastructure d’AWS à Scaleway. Apprenez de leur retour d'expérience comment stocker vos données en Europe.

Pour lancer votre première instance, il vous faudra choisir celle qui sera la plus adapté à vos besoins. C'est sur cette première étape que nous allons vous guider ici.