Créer un Plan de Reprise d’Activité Résilient pour les applications Cloud Natives : guide complet

À l’ère du cloud computing, assurer la résilience et la capacité de récupération des systèmes est crucial. Alors que les organisations comptent de plus en plus sur les applications cloud natives, un Plan de Reprise d’Activité (PRA) robuste est essentiel. Ce guide complet offre des instructions détaillées pour élaborer un PRA efficace, explore diverses options de reprise après sinistre et partage les meilleures pratiques pour la gestion des incidents.
Composants clés d’un Plan de Reprise d’Activité
Une architecture système solide
Des diagrammes détaillés et des descriptions de l’architecture de votre application cloud, incluant serveurs, bases de données et configurations réseau.
Choisir la bonne stratégie implique souvent des heures de discussions ; gardez à l’esprit qu’il n’existe pas d’architecture « infaillible », mais plutôt un équilibre entre les risques d’indisponibilité. Scaleway peut vous aider à choisir l’approche sur mesure pour votre projet.
Les héros inconnus : contact et protocoles de communication
Un annuaire de tous les membres de l’équipe PRA, leurs rôles et leurs coordonnées d’urgence.
Une équipe de reprise après sinistre dédiée et bien préparée est cruciale pour rétablir efficacement les services et atténuer l’impact des catastrophes.
Rôles essentiels :
- Responsable d’équipe : supervise l’activation du PRA et coordonne la réponse.
- Administrateurs systèmes : chargés de restaurer les sauvegardes et d’assurer l’intégrité du système.
- Ingénieurs réseaux : responsables de la sécurisation et de la restauration des configurations réseau.
- Experts en sécurité : traitent et atténuent les violations de sécurité.
- Responsables de la communication : gèrent les communications internes et externes.
Assurez-vous que votre équipe est disponible et prête à répondre 24h/24 et 7j/7. Utilisez des outils comme Splunk pour gérer les rotations de garde et les alertes.
Documentation pour les solutions de sauvegarde
Documentation explicite des emplacements de sauvegarde et des processus de restauration.
Documentation : la pierre angulaire de la récupération.
Un des piliers fondamentaux d’un PRA robuste est une documentation méticuleuse et des procédures pour restaurer et récupérer les sauvegardes. Une documentation complète sert de référence essentielle en cas d’urgence, fournissant des instructions claires et garantissant que chacun connaît ses rôles et responsabilités.
Chez Scaleway, nous comprenons cette nécessité et travaillons dur pour maintenir une documentation toujours à jour.
Quelques conclusions de nos recherches :
- 84 % des utilisateurs considèrent que la documentation produit est essentielle lors du choix d’un fournisseur de cloud.
- 76 % des utilisateurs jugent important d’avoir des exemples de cas (extraits Terraform, recettes API, etc.) dans la documentation.
- 53 % de nos utilisateurs visitent le site de documentation au moins une fois par semaine.
La Règle 3-2-1 de la Sauvegarde : copier, copier, copier
Une stratégie de sauvegarde efficace est cruciale pour tout plan de reprise d’activité. La règle 3-2-1 est une méthode éprouvée garantissant que les données sont sauvegardées de manière fiable et accessibles en cas de sinistre. La règle est simple :
- Trois copies de données : maintenez au moins trois copies de vos données.
- Deux technologies différentes : stockez les copies sur au moins deux types de supports de stockage différents.
- Une copie hors site : conservez au moins une copie hors site pour protéger contre les catastrophes locales.
Dans un contexte cloud, cela pourrait impliquer :
- Instantanés de volumes : prenez régulièrement des instantanés de vos volumes.
- Export S3 : exportez les données vers Scaleway Object Storage pour un stockage durable et évolutif.
- Copie hors site : téléchargez l’export S3 ou copiez-le dans une autre région pour garantir une redondance géographique.
Note Importante : une sauvegarde non testée est aussi bonne que pas de sauvegarde. Testez régulièrement vos sauvegardes pour vous assurer qu’elles peuvent être restaurées comme prévu.
Procédures de test :
- Exercices planifiés : réalisez des exercices réguliers simulant différents scénarios de catastrophe.
- Tests inopinés : effectuez des tests surprises pour évaluer la préparation en temps réel.
- Révision et amélioration : réalisez des bilans après chaque test pour identifier les lacunes et mettre à jour le PRA en conséquence.
Options de reprise après sinistre pour les applications Cloud Natives
Scaleway propose une gamme d’options de reprise après sinistre conçues pour répondre aux besoins spécifiques de vos applications. Explorez les solutions populaires pouvant être personnalisées pour garantir la résilience et la fiabilité de votre infrastructure cloud.
Backup and Restore Methods for Data Protection
Vue d’ensemble : sauvegardez régulièrement les données et restaurez-les en cas de catastrophe.
Avantages :
- Rentable : coûts récurrents réduits car vous ne payez que pour le stockage et les récupérations occasionnelles.
- Simplicité : facile à mettre en œuvre et à gérer, adapté aux petites et moyennes entreprises.
Inconvénients :
- Temps de récupération plus long : peut être lent à restaurer les services, entraînant des temps d’arrêt prolongés.
- Perte potentielle de données : risque de perte de données entre les intervalles de sauvegarde, selon la fréquence des sauvegardes.
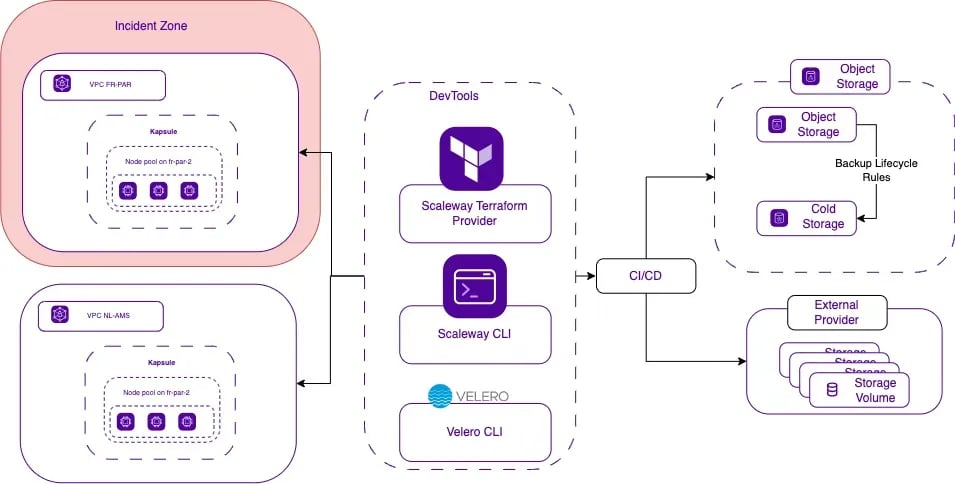
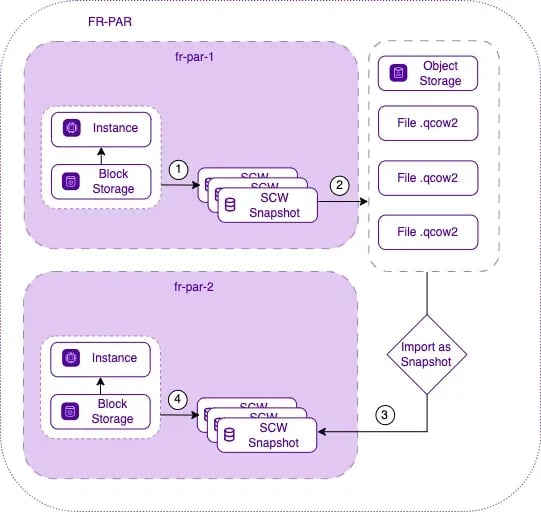
Voici le mécanisme pour transférer des instantanés dans une autre zone de disponibilité de la même région :
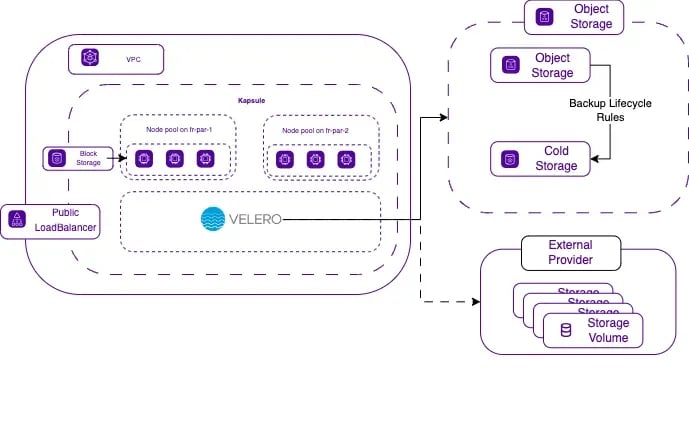
Voici comment une architecture peut être structurée pour une application basée sur des conteneurs:
Solutions de Cloud en mode Pilot Light
Vue d’ensemble : maintenez une version minimale de votre application toujours en fonctionnement, pouvant être étendue en cas de catastrophe.
Avantages :
- Récupération plus rapide : plus rapide qu’une sauvegarde complète, car les services essentiels sont déjà en fonctionnement.
- Rentabilité : coût inférieur à une solution de secours complète puisque seuls les services essentiels fonctionnent en continu.
Inconvénients :
- Complexité : nécessite une planification minutieuse pour garantir la mise à l'échelle et l’intégration.
- Capacité limitée : La capacité initiale peut être insuffisante pour gérer l’augmentation de la charge, ce qui peut compliquer la gestion des performances lors de la mise à l’échelle.
Standby Chaud
Vue d’ensemble : maintenez une version réduite mais entièrement fonctionnelle de votre application dans une autre région.
Avantages :
- Temps d’arrêt réduit : temps de récupération plus rapide avec une perte de données minimale.
- Haute disponibilité : assure que les services sont opérationnels et peuvent rapidement augmenter leur capacité.
Inconvénients :
- Coût plus élevé : plus coûteux qu’une solution Pilot Light en raison du fonctionnement continu d’un environnement fonctionnel.
- Gestion des ressources : nécessite une surveillance continue pour s’assurer que l’environnement est à jour et prêt.
Multi-Site Actif/Actif
Vue d’ensemble : faites fonctionner votre application simultanément dans plusieurs régions, offrant une capacité de basculement immédiate.
Avantages :
- Basculement immédiat : offre la plus haute disponibilité.
- Répartition de charge : équilibre la charge entre plusieurs sites, améliorant la performance et la résilience.
Inconvénients :
- Coût élevé : solution la plus coûteuse en raison du besoin de maintenir plusieurs environnements actifs, augmentant les coûts de sortie.
- Complexité : nécessite une configuration sophistiquée et une synchronisation.
Disaster Recovery as a Service (DRaaS)
Vue d’ensemble : externalisez la reprise après sinistre à un fournisseur tiers qui gère tous les aspects du PRA.
Avantages :
- Gestion simplifiée : le fournisseur gère la complexité de votre PRA.
- Expertise spécialisée : accès à une expertise spécialisée et à des technologies avancées de reprise après sinistre.
Inconvénients :
- Dépendance au fournisseur : contrôle réduit sur les événements ou le processus de récupération.
- Coût : peut être coûteux, selon les SLA et les fonctionnalités proposées.
Élaborer un Plan de Reprise d’Activité est un processus continu nécessitant des mises à jour et des améliorations régulières. N’oubliez pas la conservation, la fréquence, la sécurité et le plan de restauration ; ce sujet sera traité dans mon prochain article. Restez proactif, et votre application restera résistante face au prochain événement imprévu majeur.