
Déployez vos Mac minis Scaleway dans un environnement cloud sécurisé avec l'intégration VPC
Scaleway propose désormais Apple silicon as a Service intégré à un VPC (Cloud Privé Virtuel).

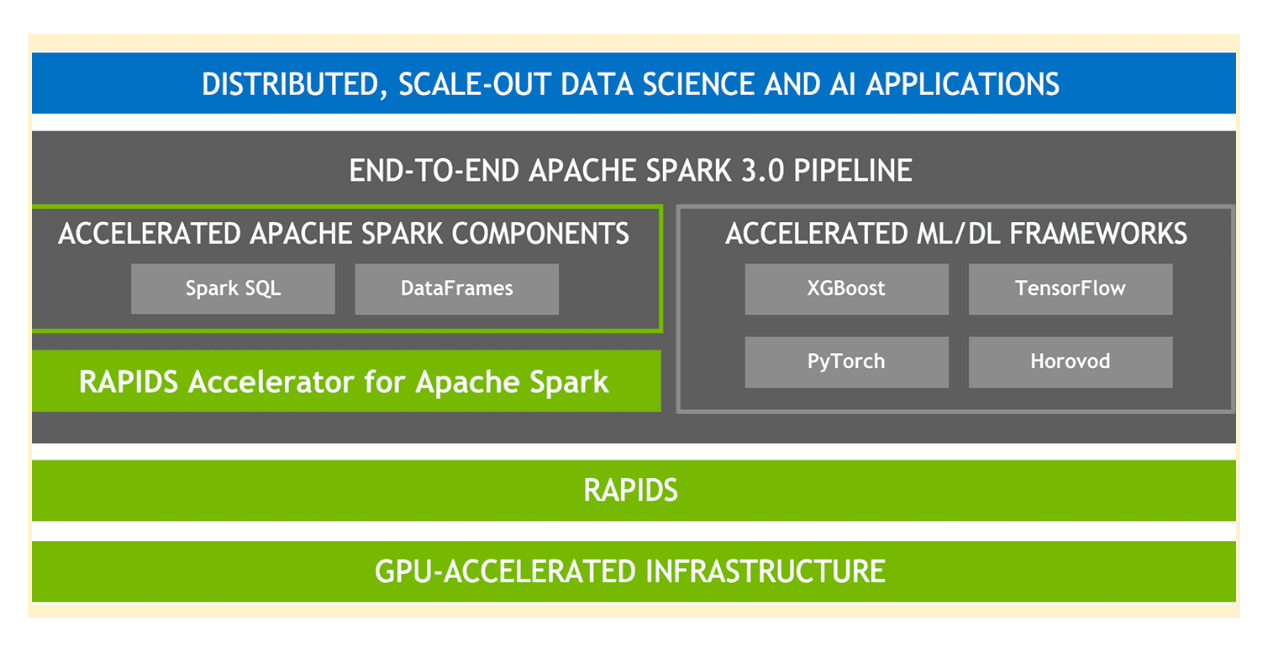
Dans le paysage en constante évolution des Big Data et du Machine Learning, Apache Spark™ s'est imposé comme un pilier essentiel pour le traitement des données. Sa capacité à gérer des quantités massives de données de manière efficace en fait un outil indispensable pour toute entreprise visant à tirer une valeur de ses données. Lorsqu'il est combiné au cadre de travail RAPIDS développé par Nvidia, les capacités d'Apache Spark™ sont considérablement augmentées, notamment en termes de traitement de données accéléré par GPU. Cette puissante association joue un rôle crucial dans la préparation des données fondamentales pour la création de modèles de langage grandeur nature (LLMs) propres à des besoins commerciaux spécifiques.
Apache Spark™ est reconnu pour sa vitesse et sa capacité à s'échelonner dans le traitement de grands ensembles de données. Ses capacités de calcul en mémoire lui permettent une analyse de données rapide, ce qui en fait le préféré des ingénieurs et scientifiques des données. Avec Apache Spark™, les entreprises peuvent gérer et analyser efficacement leurs gros volumes de données, posant les bases pour des modèles de machine learning avancés.
Cela est rendu possible par :
Le cadre de travail RAPIDS améliore les capacités d'Apache Spark™ en tirant parti de l'accélération par GPU. Développé par Nvidia et conçu pour s'intégrer avec Apache Spark™, RAPIDS offre des améliorations significatives des performances pour les tâches de traitement des données, ce qui peut entraîner des économies de coûts de jusqu'à 50% . Cela est particulièrement bénéfique pour la préparation, le nettoyage et le pré-traitement de jeux de données complexes qui sont mieux gérés par le matériel GPU.
Parmi les principaux avantages figurent :
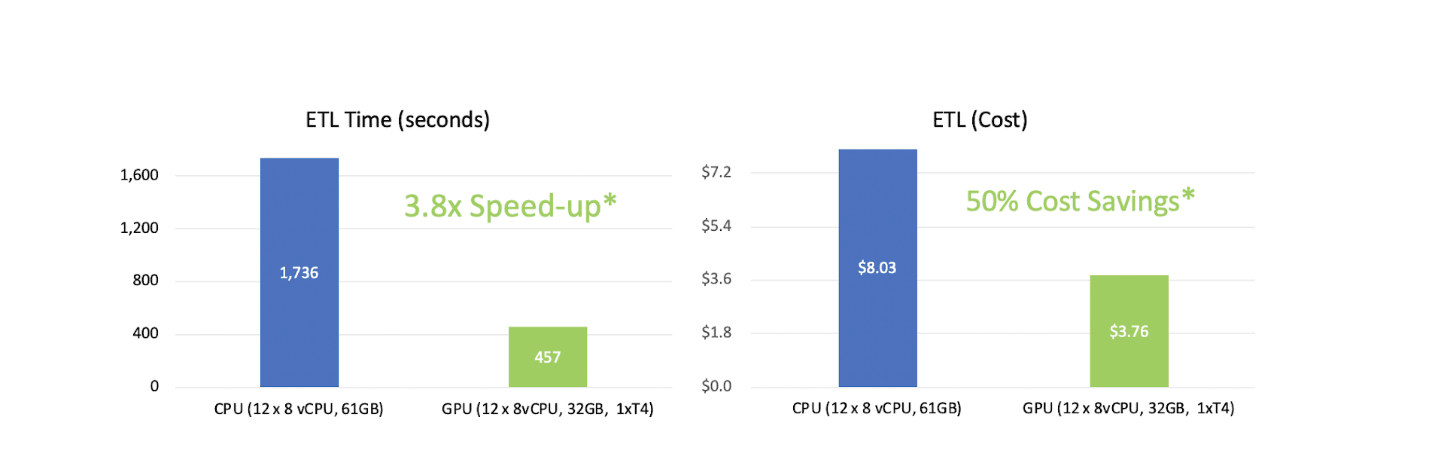
La combinaison d'Apache Spark™ et de RAPIDS offre plusieurs avantages pour les entreprises qui cherchent à exploiter leurs données pour le machine learning et l'IA. Voici quelques-uns des principaux avantages :
Comment utiliser Apache Spark™ et RAPIDS pour préparer vos données
Apache Spark™ et RAPIDS sont des outils puissants pour préparer vos données pour le machine learning et l'IA. En combinant les capacités de traitement des données d'Apache Spark™ avec l'accélération par GPU de RAPIDS, vous pouvez améliorer les performances, réduire les coûts et préparer vos données pour les modèles de machine learning avancés. En suivant les étapes décrites ci-dessus, vous pouvez utiliser Apache Spark™ et RAPIDS pour préparer vos données et atteindre vos objectifs de machine learning et d'IA.
Principaux points à retenir
Apache Spark™, renforcé par le framework RAPIDS, est un élément fondamental de l'architecture de données pour toute entreprise qui vise à exploiter et à tirer de la valeur de ses Big Data.
Prêt à révolutionner votre traitement du Big Data ? En savoir plus sur le Data Lab de Scaleway et commencer votre parcours pour construire des LLM propriétaires dès aujourd'hui.
Scaleway propose désormais Apple silicon as a Service intégré à un VPC (Cloud Privé Virtuel).

Comment comprendre et réduire l'empreinte carbone de vos infrastructures cloud, adopter les bonnes pratiques, et choisir des partenaires plus verts pour un avenir numérique durable.