Si vous avez mis en production un modèle texte-to-image et que vous cherchez à optimiser le coût de votre infrastructure, mais pas au détriment de la performance. L'Instance GPU L4 est à considérer!
L'Instance GPU L4 génère une image de 256x256px en 14445.1 pixel/seconde
- C'est 56% plus rapide qu'avec une Instance GPU Render (9278.3 pixel/seconde)
- C'est 6,3% plus rapide qu'avec une Instance GPU T4 (13583.3 pixel/seconde)
- 8,5% plus rapide qu'avec une Instance V100 PCIe GPU (16G) (13314.6 pixel/seconde)
- 8,2 % plus rapide que l'instance V100 SXM2 GPU (16G) (13348,8 pixels/seconde)
- Et presque aussi rapide qu'avec une Instance A100 SXM 40GB (-1,6%) (14681.1pixel/seconde)
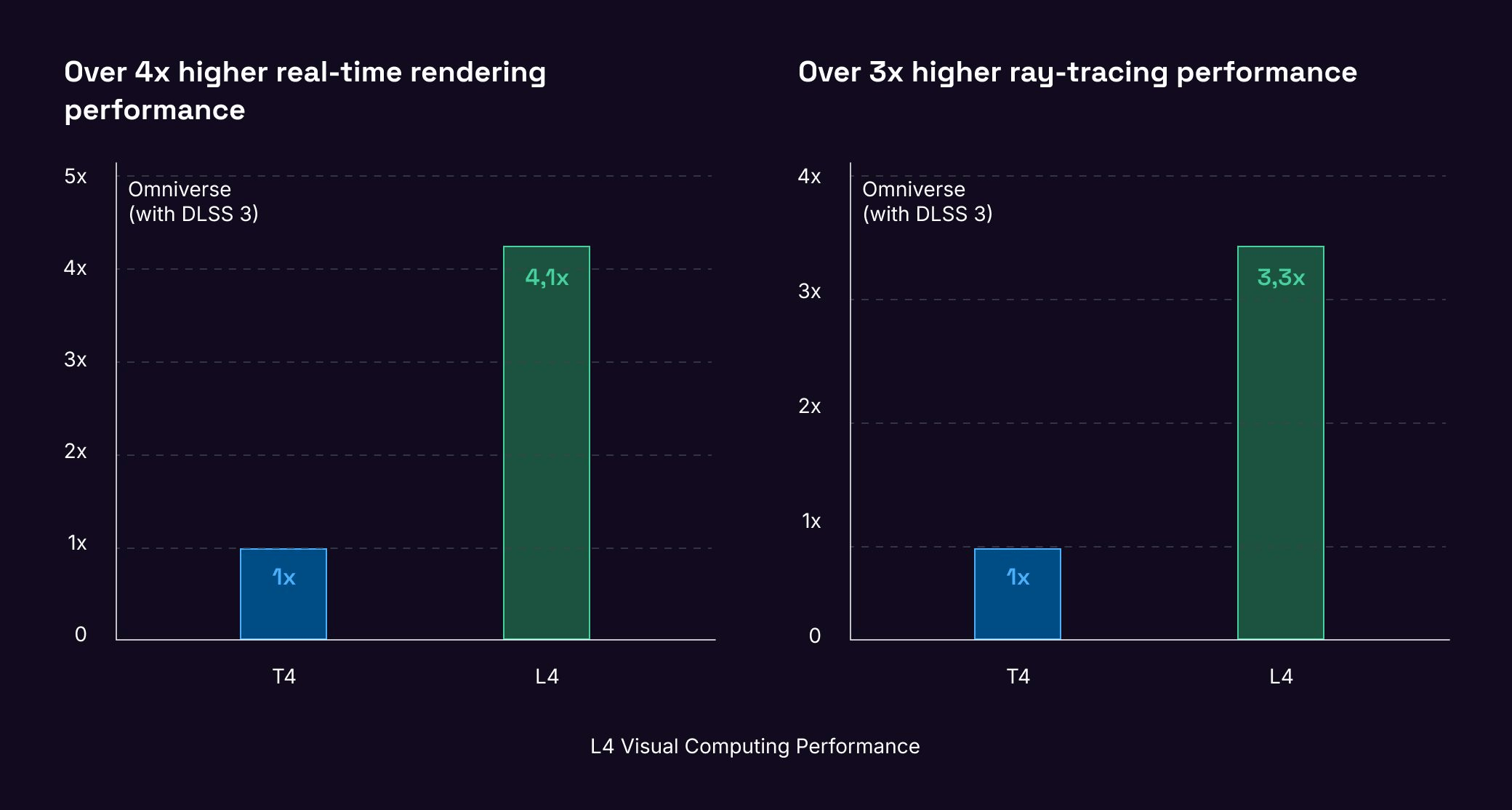
Avec une capacité de mémoire accrue de 50 % par rapport la génération précédente GPU T4, la L4 permet de générer des images plus grandes, jusqu'à 1024x768.
Source :
Le modèle a testé InvokeAI, un framework open-source populaire pour la génération et la modification d'images. De plus, [Cloud Mercato a créé invokeai-benchmark](https://projector.cloud-mercato.com/projects/scaleway-nvidia-h100/invokeai/graph), un outil pratique qui rend nos tests et notre méthodologie plus facilement reproductibles.